До запуска бета-версии API Ноушен наша команда шутила, что каждый анонс продукта сопровождался общим рефреном:
NOTION: публикует твит, в котором не упоминается API.
Пользователи: «Где API?».
Пользователи, которые хотели расширить возможности Ноушен, испытывали огромный аппетит к API. Наша миссия — сделать создание программных инструментов повсеместным. Чтобы эффективно выполнять эту задачу в современном взаимосвязанном мире, Ноушен должен работать с другими инструментами, на которые уже полагаются пользователи.
Многие пользователи справедливо спрашивают: «Разве создание REST API — это не хорошо освоенная территория? Что может быть таким сложным?» Это обоснованные вопросы, особенно в мире, где есть API практически для всего, начиная от данных фэнтези-спорта и заканчивая рецензиями на фильмы в New York Times. Что отличает компанию Ноушен?
Оказывается, разработка хорошего API для такой гибкой платформы, как Ноушен, представляет собой удивительно сложную задачу! Мы делимся некоторыми ключевыми решениями из нашего процесса в надежде, что наш опыт поможет другим разработчикам понять, что делает API Ноушен уникальным.
Представление содержимого страницы
Мы уже писали о модели данных Ноушен, но вкратце: контент разделен на блоки. Все является блоком, от изображений и элементов списка до строк базы данных и самих страниц.
Суть нашей проблемы проектирования API заключается в том, как перевести произвольные деревья богато отформатированного пользовательского контента в последовательный API, который легко интегрируется с другими рабочими процессами. Давайте разделим эту проблему на две части: структурирование текста внутри блоков и иерархическая структура между блоками.
Встроенное форматирование насыщенного текста
Внутри каждого блока Ноушен поддерживает богатое разнообразие операций форматирования текста, начиная от стандартных полужирного и курсивного начертания и заканчивая выделением, уравнениями f(x) = x^2 + 1 и многим другим. Не все эти стили являются стандартными, поэтому нам понадобилось переносимое представление и для текста.
Когда мы решали, как представить содержимое страницы в API, было два основных претендента:
- низкая точность, высокая переносимость: Markdown, популярный синтаксис для человекочитаемого форматирования обычного текста. Это широко поддерживаемый формат с надежным существующим инструментарием, а редактор Ноушен уже поддерживает ярлыки Markdown и экспорт.
- Высокая точность, низкая переносимость: Пользовательский JSON, основанный на нашем внутреннем представлении значений блоков Ноушен. Настроенная схема будет отражать специфические для Ноушен типы блоков и форматирование, за счет того, что пользователям придется как-то преобразовывать эти данные в желаемый формат вывода.
Помимо компромисса между верностью и портативностью, есть несколько моментов в пользу Markdown:
- Меньшая нагрузка на внедрение и обслуживание: Мы хотели сделать API как можно более эффективным. Используя Markdown, мы могли воспользоваться существующей функциональностью Ноушен по импорту и экспорту Markdown, вместо того чтобы разрабатывать новый формат данных.
- Меньше ломающих изменений: Плюсом низкой точности Markdown является то, что мы можем легко изменить способ представления блоков, используя ограниченное количество доступных конструкций. С другой стороны, при использовании пользовательского JSON каждый новый или обновленный тип блока потребует от нас изменения формата JSON и, возможно, выпуска новой версии API.
Однако самая большая проблема с Markdown заключается в том, что он просто недостаточно выразителен для поддержки тех случаев использования, для которых наши пользователи хотели бы иметь API, например, пользовательских импортеров и экспортеров для ввода и вывода данных из Ноушен, или интеграций, использующих Ноушен в качестве CMS или резервного хранилища данных. Люди называют Ноушен «чистым холстом» и «местом для нестандартного мышления», потому что он такой гибкий и выразительный. Если бы наш API не мог воспроизвести то, что пользователи потратили драгоценное время на создание в Ноушен, его мощь и полезность были бы снижены.

Разработчики часто удивляются, узнав, что канонический справочник по языку Markdown описывает относительно ограниченный набор конструкций форматирования.¹ Синтаксис для таблиц, зачеркивание в строке и огражденные блоки кода — функции, тесно связанные с Markdown сегодня — появились только тогда, когда все больше людей начали адаптировать язык к своим потребностям, что вызвало Кембрийский взрыв диалектов и цепочек инструментов (см. GitHub-Flavored Markdown, MultiMarkdown, PHP Markdown Extra, R Markdown, CommonMark и бесчисленные специальные реализации).
Документы из одного редактора Markdown часто будут по-разному анализироваться и отображаться в другом приложении. Несоответствие, как правило, устранимо для простых документов, но это большая проблема для богатой библиотеки блоков и встроенных опций форматирования Ноушен, многие из которых просто не поддерживаются ни в одной широко используемой реализации Markdown. Чтобы сохранить пользовательский контент как можно точнее, мы решили разработать собственное представление JSON для насыщенного текста.
Пагинация иерархий блоков
Еще одно достоинство пользовательского JSON заключается в том, что он облегчает постраничную сортировку дерева содержимого, что необходимо для получения больших страниц. Большинство блоков поддерживают неограниченное количество дочерних блоков, вложенных произвольно глубоко — представьте себе сложный контур списка или иерархию подстраниц вашего рабочего пространства.
Такая неограниченная структура превращает, казалось бы, простой запрос, например «получить содержимое страницы с рецептами», в более сложную проблему: как мы должны дозировать блоки содержимого в ответе?
- В первую очередь: Возвращать партии блоков верхнего уровня, без дочерних блоков. Требуйте от разработчиков отдельно запрашивать дочерние блоки для «завершения» отдельного блока. Эта модель имеет наибольший смысл с точки зрения производительности, но клиентам сложнее получить полную страницу: им приходится делать больше запросов в целом и выполнять вставку дерева, чтобы собрать ответы.
- Глубина-первая: Возвращают полные блоки, но за счет того, что требуется больше вызовов для запроса блоков верхнего уровня дальше по странице. Эта модель более точно соответствует интуиции большинства людей о «возврате содержимого, начиная с самого начала и далее по странице». Однако маршаллинг одного глубоко вложенного блока может потребовать неограниченного количества времени, что в первую очередь противоречит цели пагинации.
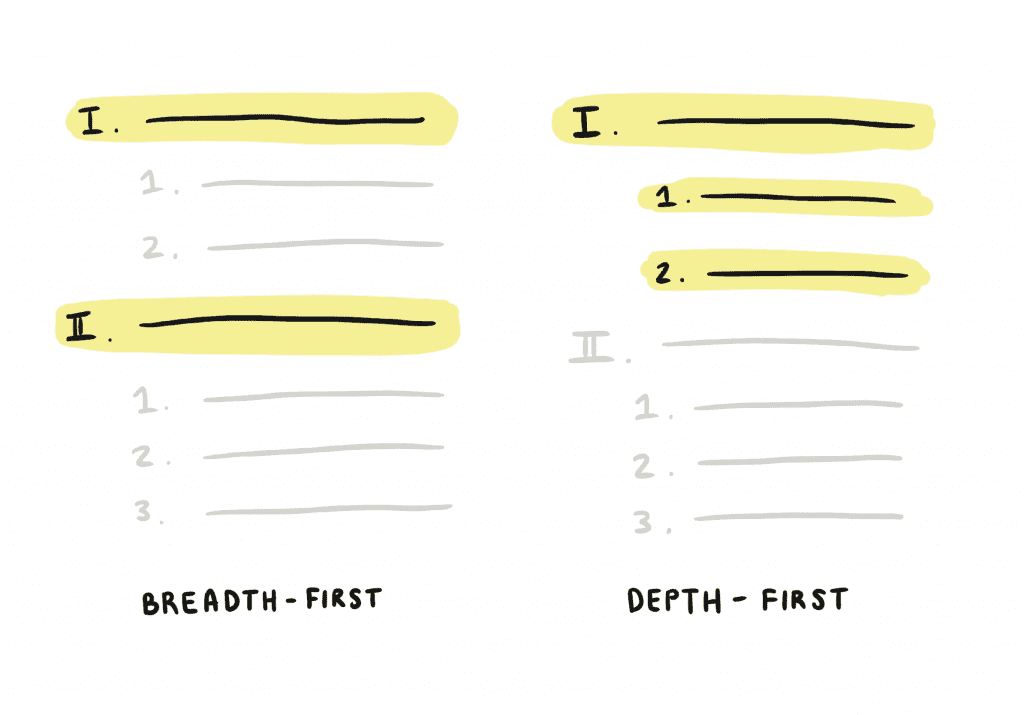
По соображениям производительности мы выбрали пагинацию в первую очередь, что напрямую повлияло на представление документов. Пагинация JSON довольно проста, поскольку блоки сохраняют свои UUID и другие структурные метаданные. Но поскольку документы Markdown не имеют большой структуры (кроме символов новой строки), пагинация Markdown намного сложнее.
Например, в модели «по широте охвата» нам придется обозначать незаконченные абзацы какими-то маркерами. Этим маркерам нужны идентификаторы, чтобы помочь клиентам вставить подпараграфы в правильное положение:
I. Introduction ... <!-- 8215b034-6785-4082-a572-b9ce7fe6f8d0 -->II. Goals ... <!-- 2724af5c-8122-4127-a978-37067c37f745 --> Очень скоро мы изобрели бы еще один вариант Markdown и потребовали бы от разработчиков выполнять тонны манипуляций со строками! Было ясно, что простота Markdown не распространяется на нашу сложную модель документов, что закрепило наше решение использовать пользовательский JSON, чтобы предоставить разработчикам большую точность и контроль.² В будущем наша команда (или сообщество разработчиков) всегда может создать инструменты преобразования для перевода нашего пользовательского JSON в стандартные форматы.
Выбор формата данных связан с другим вопросом: как развивать API со временем. Здесь, как правило, есть два подхода:
- Версионирование для каждого ресурса: Каждая конечная точка версионируется и обновляется индивидуально, либо по URI
(/v2/users), либо по заголовкуContent-Type (Accept: application/notion.v2+json).Версионность ресурсов позволяет нам вносить изолированные изменения, но крупные обновления могут потребовать от клиентов обновления каждого URL, не говоря уже о головной боли, связанной с зависимостями между конечными точками (если/v2/pagesтребует/v3/databasesили т.п.). - Глобальное версионирование: Любое изменение создает новую глобальную версию API. Когда это применяется, запросы должны включать заголовок с указанием желаемой версии API, иначе считается, что они используют версию, доступную на момент выдачи токена.
Мы выбрали глобальное версионирование, используя подход в стиле Stripe и AWS — помечать версии датой выпуска, а не указывать основные версии в URI (api-v2.notion.com). Мы посчитали, что маркировка версий датой выпуска будет способствовать формированию этики небольших, безопасных переходов на новые версии с соответствующими недорогими обновлениями, а не серьезных ломающих изменений, подразумеваемых при переходе от v2 к v3.
Получение свойств страницы
До сих пор мы говорили в основном о документах, созданных из текста. Но Ноушен предназначен не только для заметок и списков дел — мы также поддерживаем пользовательские базы данных. Страницы в базе данных могут иметь свойства, основанные на схеме базы данных. Поэтому нам понадобился способ, с помощью которого пользователи могли бы запрашивать свойства страниц, и это оказалось на удивление сложной задачей!
Большинство свойств — это простые значения, такие как человек, назначенный на проект, или список тегов. Когда пользователь запрашивает эти простые свойства страницы, мы можем просто вернуть JSON-представление базовых данных для каждого из них:

Мы также поддерживаем более продвинутые свойства страниц, такие как отношения и сворачивание. Эти свойства делают Ноушен особенно мощным для реляционного моделирования данных.
- Отношения позволяют пользователям связывать страницы в разных базах данных.
Например, предположим, что вы владелец малого бизнеса, занимающийся производством одежды. У вас может быть база данных 🔖 Products с ценой на каждый товар и другими деталями производства, и база данных 👥 Customers с постоянными покупателями. Создание связи между этими базами данных позволит вам отслеживать, кто что купил, в обоих направлениях.
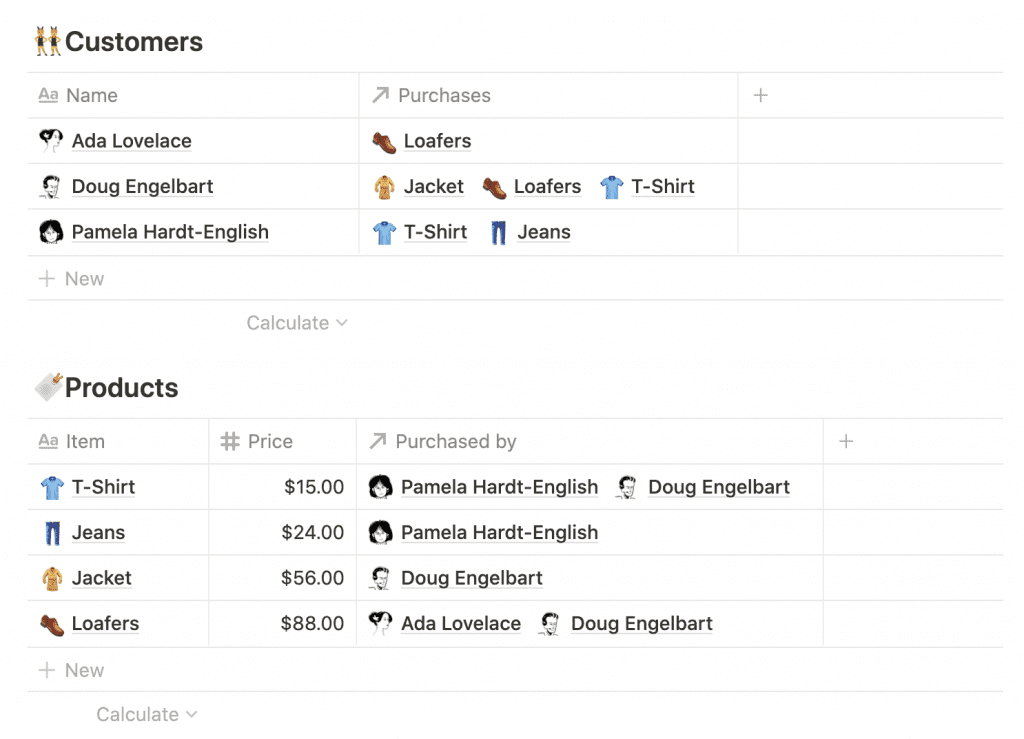
- Свертки используются для объединения свойств связанных страниц.
Свертка состоит из трех компонентов: связанной базы данных, свойства из этой базы данных и операции, которую нужно выполнить над этим свойством. Например, чтобы определить лучших клиентов, можно настроить свойство сворачивания в 👥 Customers, чтобы показать, сколько каждый клиент потратил:- Связанная база данных: 🔖 Продукты
- Свойство: Цена (число)
- Операция: Сумма
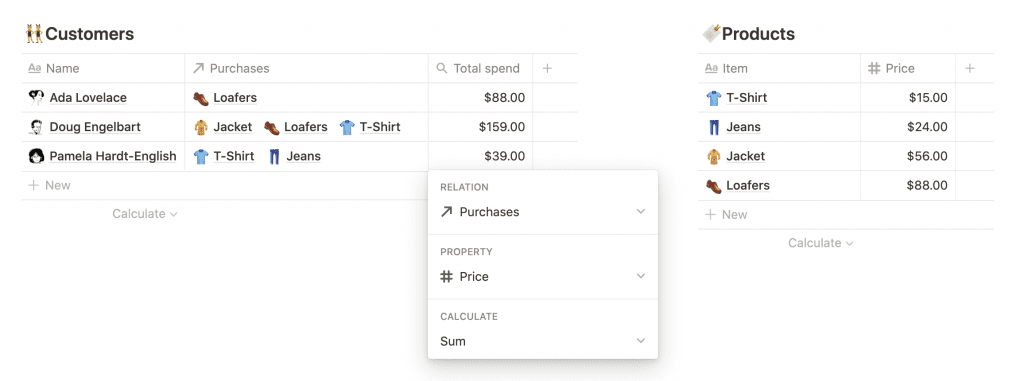
Для каждого покупателя сворачивание просматривает все приобретенные продукты, извлекает цену каждого продукта и суммирует все.
Свертки не ограничиваются числовыми свойствами: вы можете суммировать и связанные страницы. Здесь мы настраиваем сворачивание для базы данных 🔖 Products, чтобы отслеживать, сколько раз был продан каждый продукт.
- Связанная база данных: 👥 Customers
- Свойство: Покупки (отношение)
- Операция: Подсчитать всех
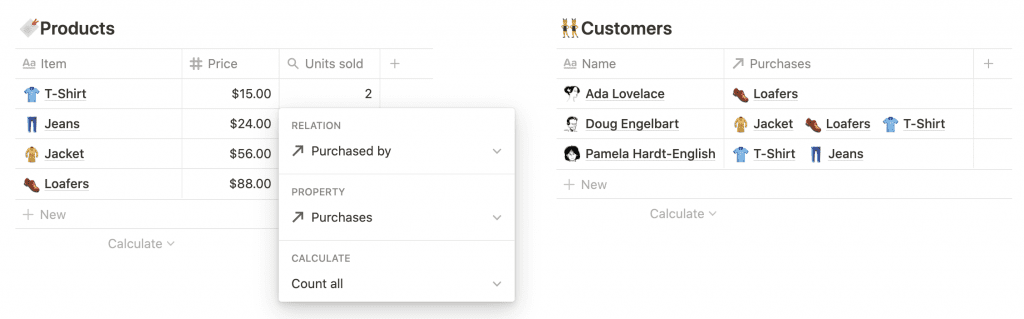
Внутри сайта мы храним отношения в нормализованной форме. Это означает, что для данной страницы продукта связанные клиенты хранятся в виде массива UUID страниц, которые служат внешними ключами для базы данных 👥 Customers.
Очевидно, что мы не можем отобразить эти UUID непосредственно пользователю, поэтому всякий раз, когда мы загружаем отношение, нам нужно просмотреть каждую связанную страницу, чтобы получить ее человекочитаемые свойства. Это означает, что загрузка одного свойства отношения может вызвать множество поисков: по одному для каждой связанной страницы в другой базе данных!
Свертки добавляют еще один уровень сложности. Поскольку сворачивание объединяет свойства всех связанных страниц, вычисление сворачивания начинается с загрузки свойства отношения, как описано выше. Затем, в зависимости от операции, мы должны извлечь соответствующее свойство из каждой связанной страницы и объединить свойства страниц. Простые операции, такие как Count all, достаточно просты, но такие операции, как Sum или Average, требуют отслеживания промежуточного состояния.
Каковы же практические последствия всего этого? Чем больше отношений и рулонов включено в страницу, тем больше поисков и маршалов необходимо выполнить API, и тем больше будет время отклика. Для использования в масштабах предприятия неограниченная задержка станет огромной проблемой.
Пагинация отношений
Стандартным решением для вычисления данных произвольного размера является пагинация: вместо того, чтобы загружать и возвращать все результаты сразу, мы выдаем по одному пакету фиксированного размера за раз, предоставляя клиенту дескриптор для запроса следующей порции результатов.
Пагинация предполагает, что результаты можно упорядочить. Существует два основных способа позволить клиентам ориентироваться в этом порядке:
- На основе смещения: Прост для разработчиков, но может рассинхронизироваться, если базовые данные обновляются в реальном времени.
- На основе курсоров: Курсоры могут быть ссылками на состояния прокрутки на стороне сервера, или они могут кодировать параметры запроса напрямую, используя Base 64 или аналогичную кодировку.
Поскольку пользователи могут обновлять отношения в режиме реального времени, мы решили реализовать пагинацию на основе курсора для загрузки свойств отношения. Это позволяет нам возвращать ограниченное количество страниц из свойства отношения, а клиенты могут выполнять дополнительные запросы, пока не будут возвращены все страницы.
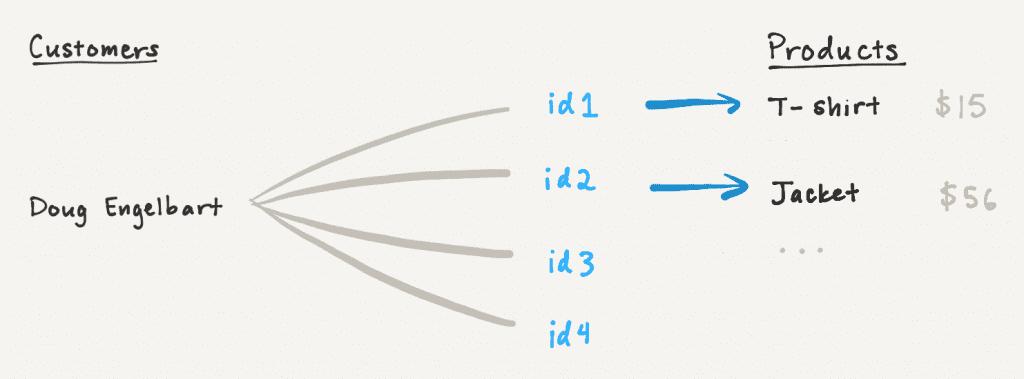
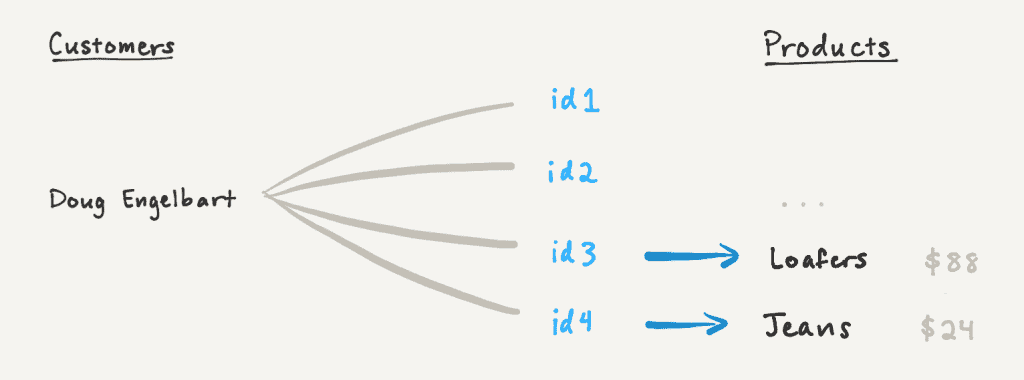
Пагинация числовых сворачиваний
Мы можем повторно использовать эту логику пагинации для рулонов, поскольку загрузка рулона требует загрузки базового отношения. Но есть одна загвоздка: как и формулы электронных таблиц, сворачивания вычисляются в реальном времени на основе связанных страниц, а поскольку мы загружаем связанные страницы постепенно, у нас может не быть всех данных, необходимых для вычисления окончательного значения сворачивания!
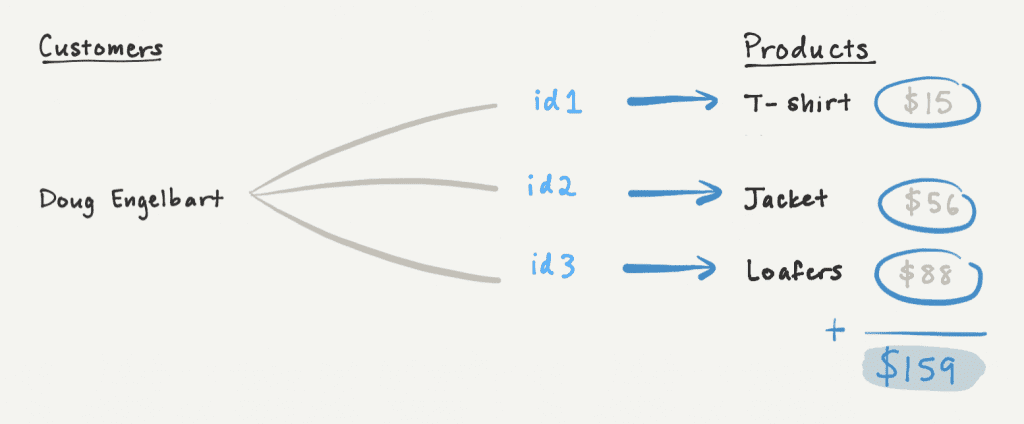
Для примера рассмотрим сводку «Общие расходы», которая суммирует стоимость всех покупок одежды Дуга Энгельбарта. Если мы будем загружать отношение «Покупки» партиями по два, первый ответ будет включать только общую стоимость загруженных на данный момент страниц, что не отражает общую сумму расходов Дуга.
Однако мы можем вычислить частичный результат для первых двух страниц и занести этот результат в курсор в качестве аккумулятора. Когда клиент сделает еще один запрос с помощью курсора, мы можем обновить накопитель на основе вновь загруженных страниц. Когда все страницы будут загружены, накопитель будет отражать окончательное значение сворачивания.
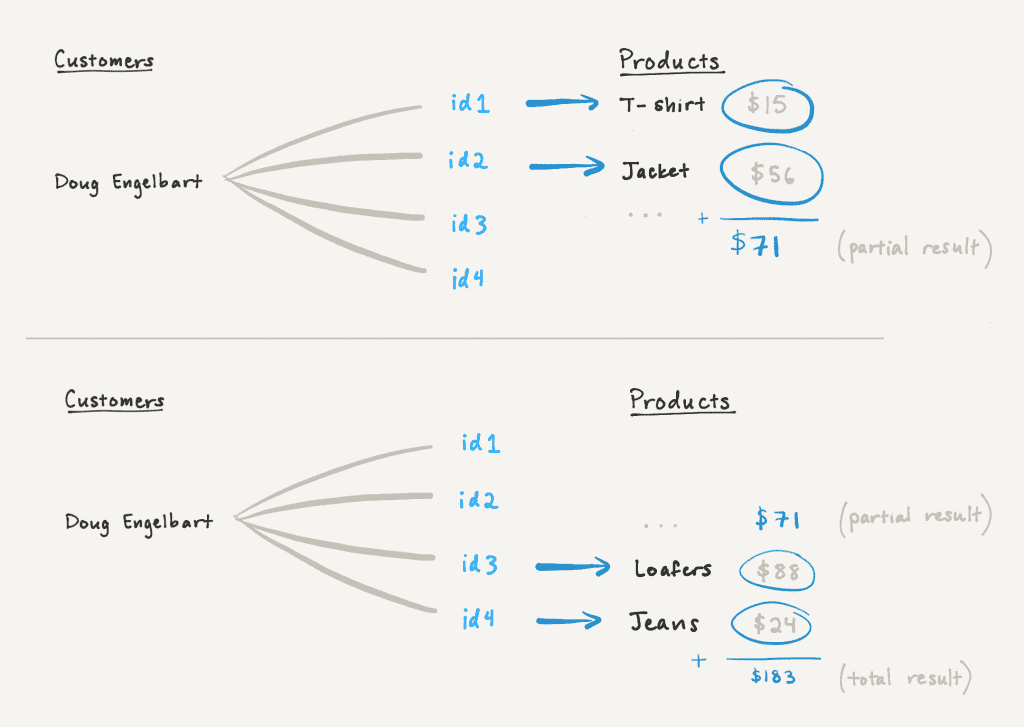
Для постраничной обработки сворачивания суммы мы вычисляем частичную сумму для каждой партии связанных страниц. Каждый ответ включает курсор, кодирующий следующую страницу и частичную сумму всех загруженных на данный момент страниц. Последующие извлечения могут включать эту частичную сумму, пока все страницы не будут загружены и сумма не будет отражать всю связь.
Кодирование результата в курсор работает для многих видов сворачивания, включая Sum, Count и Max. Для Average нам также необходимо отслеживать количество загруженных страниц, чтобы правильно взвесить частичное среднее. В более общем случае наш подход работает для любого сворачивания со следующими свойствами:
- Смущающе параллельный: Мы можем разделить проблему на независимые подпроблемы и объединить частичные результаты, чтобы в итоге получить глобальный результат. Это требование исключает свертки типа Median, которые не могут быть разделены на подзадачи, пока все страницы не будут глобально упорядочены — что потребует загрузки всех страниц для начала.
- Сублинейное представление пространства: Нам нужно, чтобы накопитель(и) рос(ли) медленно, чтобы закодировать их в курсоре без ущерба для эргономики. Например, Sum и Average являются постоянным пространством в JavaScript, где все числа занимают 64 бита независимо от размера. Это требование исключает использование рулонов типа Show unique values, который можно распараллелить (просто вычислить уникальные значения в каждом подмножестве), но который требует линейно увеличивающегося объема пространства (для кодирования всех уникальных значений, увиденных на данный момент). Такой курсор в Base64-кодировке быстро станет громоздким.
Для тех немногих типов сворачиваний, которые мы не можем использовать MapReduce, мы просто возвращаем базовые значения отношений, чтобы клиент мог вычислить их напрямую.
Строительство для наших пользователей
При таком большом спросе на API было бы легко упустить наше стремление к качеству в пользу быстрой доставки. Но мы хотели, чтобы API соответствовал обещаниям самого Ноушен: мощный, гибкий инструмент, который вы можете использовать для решения своих проблем. Иногда для достижения этой цели приходится идти сложным путем: вводить пользовательское представление страниц в формате JSON, внедрять версионность до запуска бета-версии или разрабатывать новую схему пагинации для обработки сложных зависимостей данных.
Однако тяжелая работа приносит еще больше плодов, когда пользователи создают невероятные вещи с помощью созданных нами инструментов. Если вы хотите попробовать бета-версию API, зайдите на наш сайт для разработчиков, чтобы начать работу. А если вы мечтаете о каком-то конкретном функционале, перейдите на страницу карьеры, чтобы начать работу и над этим.