За последние три года объем данных Ноушен увеличился в 10 раз за счет роста пользователей и контента, причем удвоение происходило с периодичностью 6-12 месяцев. Управление таким быстрым ростом и удовлетворение постоянно растущих потребностей в данных для критически важных продуктов и аналитических приложений, особенно для наших недавних функций Ноушен AI, означало создание и масштабирование озера данных Ноушен. Вот как мы это сделали.
Модель данных и рост компании Ноушен
Все, что вы видите в Ноушен — тексты, изображения, заголовки, списки, строки базы данных, страницы и т. д. — несмотря на различия во внешнем представлении и поведении, моделируется как «блочная» сущность в задней части и хранится в базе данных Postgres с согласованной структурой, схемой и связанными метаданными (подробнее о модели данных Ноушен).

Все эти блочные данные удваиваются каждые 6-12 месяцев, что обусловлено активностью пользователей и созданием контента. В начале 2021 года в Postgres было более 20 миллиардов блочных строк, и с тех пор эта цифра выросла до более чем двухсот миллиардов блоков — объем данных составляет сотни терабайт, даже в сжатом виде.
Чтобы справиться с этим ростом данных и одновременно повысить удобство работы пользователей, мы стратегически расширили нашу инфраструктуру баз данных, перейдя от одного экземпляра Postgres к более сложной шардированной архитектуре. В 2021 году мы начали с горизонтального разбиения базы данных Postgres на 32 физических экземпляра, каждый из которых состоял из 15 логических шардов, а в 2023 году увеличили количество физических экземпляров до 96, с пятью логическими шардами на экземпляр. Таким образом, мы сохранили в общей сложности 480 логических шардов, обеспечив при этом долгосрочное масштабируемое управление и поиск данных.
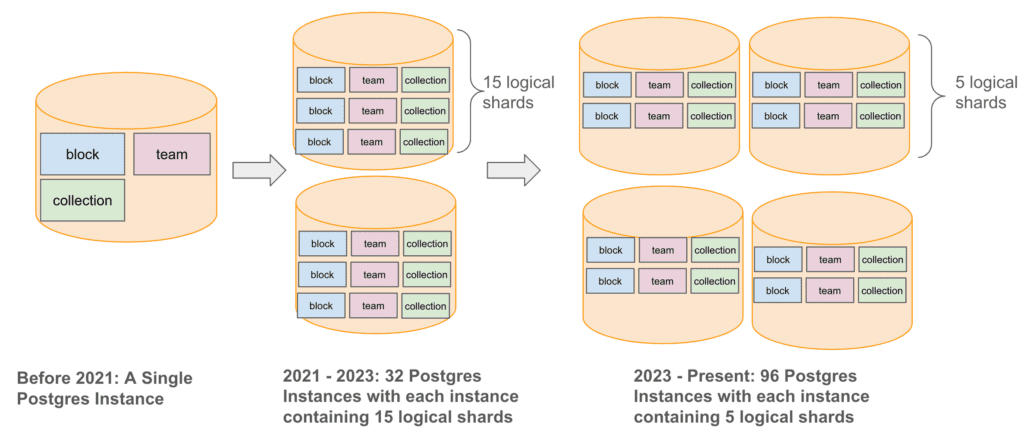
Архитектура хранилища данных Ноушен в 2021 году
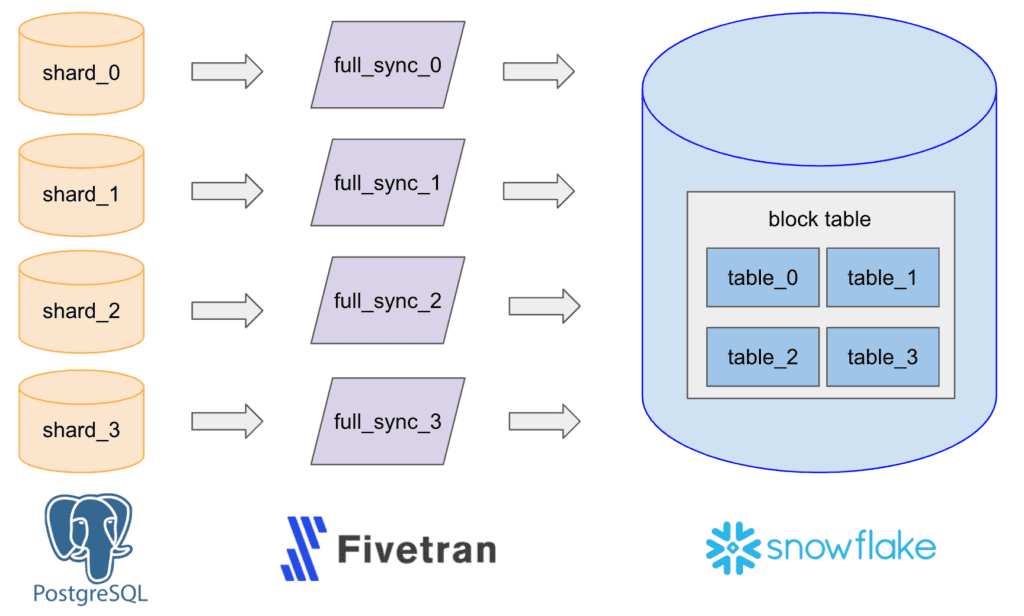
В 2021 году мы запустили эту специализированную инфраструктуру данных с помощью простого конвейера ELT (Extract, Load, and Transform), который использовал сторонний инструмент Fivetran для ввода данных из Postgres WAL (Write Ahead Log) в Snowflake и настроил коннекторы для 480 шардов с почасовой обработкой для записи в такое же количество необработанных таблиц Snowflake. Затем мы объединили эти таблицы в одну большую таблицу для аналитики, отчетности и машинного обучения.
Проблемы масштабирования
По мере роста данных Postgres мы столкнулись с несколькими проблемами масштабирования.
Работоспособность
Накладные расходы на мониторинг и управление 480 коннекторами Fivetran, а также их повторная синхронизация в периоды решардинга, обновления и обслуживания Postgres стали чрезвычайно высокими, что создавало значительную нагрузку на членов команды, работающих по вызову.
Скорость, свежесть данных и стоимость
Загрузка данных в Snowflake стала более медленной и дорогостоящей, в первую очередь из-за уникальной нагрузки, связанной с обновлением данных в Ноушен. Пользователи Ноушен обновляют существующие блоки (тексты, заголовки, названия, маркированные списки, строки базы данных и т. д.) гораздо чаще, чем добавляют новые. Это приводит к тому, что данные в блоках преимущественно обновляются — 90 % обновлений в Ноушен приходится на обновления. Большинство хранилищ данных, включая Snowflake, оптимизированы для работы с большими объемами вставок, поэтому им все труднее принимать блочные данные.
Поддержка сценариев использования
Логика преобразования данных становилась все более сложной и тяжелой, превосходя возможности стандартного интерфейса SQL, предлагаемого готовыми хранилищами данных.
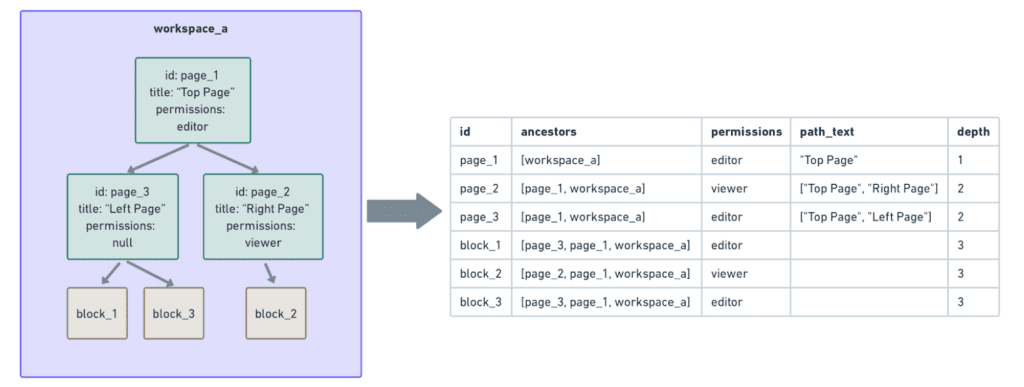
- Одним из важных вариантов использования является построение денормализованных представлений блочных данных Ноушен для ключевых продуктов (например, AI и Search). Данные о разрешениях, например, гарантируют, что только нужные люди могут читать или изменять блок (в этом блоге обсуждается модель разрешений блока Ноушен). Но разрешение блока не хранится статически в связанном с ним Postgres — его приходится создавать на лету с помощью дорогостоящих вычислений обхода дерева.
- В следующем примере block_1, block_2 и block_3 наследуют разрешения от своих непосредственных родителей (page_3 и page_2) и предков (page_1 и workspace_a). Чтобы построить данные о разрешениях для каждого из этих блоков, мы должны обойти дерево их предков вплоть до корня ( workpace_a), чтобы обеспечить полноту. При наличии сотен миллиардов блоков, глубина предков которых варьировалась от нескольких до десятков, подобные вычисления были очень дорогостоящими и в Snowflake просто не успевали выполняться.
В связи с этими проблемами мы начали изучать возможность создания озера данных.
Создание и масштабирование собственного озера данных Ноушен
Вот какие цели мы преследовали, создавая собственное озеро данных:
- Создайте хранилище данных, способное хранить как необработанные, так и обработанные данные в масштабе.
- Обеспечение быстрого, масштабируемого, оперативного и экономически эффективного ввода данных и вычислений для любых рабочих нагрузок, особенно для блокчейн-данных Ноушен с большим количеством обновлений.
- Разблокируйте возможности ИИ, поиска и других приложений, требующих денормализованных данных.
Однако, несмотря на то, что наше озеро данных — это большой шаг вперед, важно уточнить, для чего оно не предназначено:
- Полностью заменить Snowflake. Мы продолжим пользоваться преимуществами Snowflake в плане операционной и экосистемной простоты, используя его для большинства других рабочих нагрузок, особенно тех, которые требуют большого количества вставок и не нуждаются в масштабном денормализованном обходе деревьев.
- Полностью заменить Fivetran. Мы продолжим использовать преимущества Fivetran при работе с тяжелыми таблицами без обновлений, при вводе небольших наборов данных, а также при работе с различными сторонними источниками и местами назначения данных.
- Поддержка онлайновых сценариев использования, требующих второго уровня или более жесткой латентности. Озеро данных Ноушен будет ориентировано в первую очередь на автономные рабочие нагрузки, которые могут выдержать задержку от нескольких минут до нескольких часов.
Высокоуровневый дизайн нашего озера данных
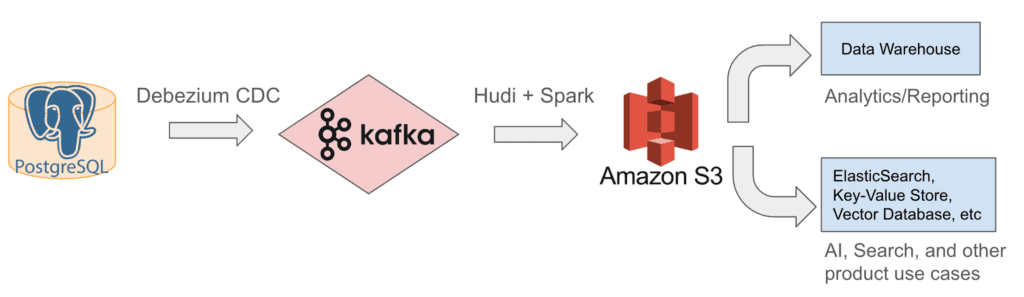
С 2022 года мы используем внутреннюю архитектуру озера данных, показанную ниже. Мы получаем постепенно обновляемые данные из Postgres в Kafka с помощью коннекторов Debezium CDC, а затем используем Apache Hudi, фреймворк для обработки и хранения данных с открытым исходным кодом, для записи этих обновлений из Kafka в S3. С этими необработанными данными мы можем выполнять трансформацию, денормализацию (например, обход деревьев и построение данных разрешений для каждого блока) и обогащение, а затем снова хранить обработанные данные в S3 или в последующих системах, чтобы обслуживать аналитику и отчетность, а также AI, Search и другие требования к продуктам.
Далее мы опишем и проиллюстрируем принципы дизайна и решения, к которым мы пришли после длительных исследований, обсуждений и создания прототипов.
Проектное решение 1: выбор хранилища и озера данных
Первым нашим решением было использовать S3 в качестве хранилища и озера данных для хранения всех необработанных и обработанных данных, а хранилище данных и другие хранилища данных, ориентированные на продукт, такие как ElasticSearch, Vector Database, Key-Value store и т. д., расположить в качестве последующей обработки. Мы приняли это решение по двум причинам:
- Он соответствует технологическому стеку AWS компании Ноушен, например, наша база данных Postgres основана на AWS RDS, а ее функция экспорта в S3 (описанная в последующих разделах) позволяет нам легко загружать таблицы в S3.
- S3 доказал свою способность хранить большие объемы данных и поддерживать различные механизмы обработки данных (например, Spark) при низких затратах.
Перегрузив тяжелые рабочие процессы по обработке данных и вычислениям в S3 и загружая в Snowflake и хранилища данных, ориентированные на продукт, только высокоочищенные и важные для бизнеса данные, мы значительно повысили масштабируемость и скорость вычислений данных и снизили затраты.
Проектное решение 2: выбор движка для обработки данных
Мы выбрали Spark в качестве основного механизма обработки данных, потому что, будучи фреймворком с открытым исходным кодом, его можно быстро настроить и оценить, насколько он соответствует нашим потребностям в преобразовании данных. У Spark есть четыре ключевых преимущества:
- Широкий спектр встроенных функций Spark и UDF (User Defined Functions), выходящих за рамки SQL, позволяет использовать такие сложные логики обработки данных, как обход деревьев и денормализация блочных данных, как описано выше.
- Он предлагает удобный фреймворк PySpark для большинства легких сценариев использования и усовершенствованный Scala Spark для высокопроизводительной обработки тяжелых данных.
- Он обрабатывает большие данные (например, миллиарды блоков и сотни терабайт) распределенным образом и предоставляет широкие возможности конфигурации, что позволяет нам точно настроить контроль над разбиением, перекосом данных и распределением ресурсов. Он также позволяет нам разбивать сложные задания на более мелкие и оптимизировать ресурсы для каждого задания, что помогает нам достичь разумного времени выполнения без избыточного выделения или пустой траты ресурсов.
- Наконец, открытый исходный код Spark обеспечивает экономическую эффективность.
Проектное решение 3: Предпочтение инкрементного ввода данных перед сбрасыванием моментальных снимков
После завершения разработки механизма хранения и обработки данных для озера данных мы изучили решения для загрузки данных Postgres в S3. В итоге мы рассмотрели два подхода: инкрементный захват измененных данных и периодические полные снимки таблиц Postgres. В итоге, сравнив производительность и стоимость, мы остановились на гибридном варианте:
- Во время нормальной работы инкрементально загружайте и постоянно применяйте измененные данные Postgres в S3.
- В редких случаях один раз сделайте полный снимок Postgres, чтобы загрузить таблицы в S3.
Инкрементный подход обеспечивает более свежие данные при меньших затратах и минимальной задержке (от нескольких минут до пары часов, в зависимости от размера таблицы). Создание полного снимка и сброс данных в S3, напротив, занимает более 10 часов и обходится вдвое дороже, поэтому мы делаем это нечасто, при загрузке новых таблиц в S3.
Проектное решение 4: оптимизация инкрементного ввода данных
- Kafka CDC Connector for Postgres → to → Kafka
Мы выбрали коннектор Kafka Debezium CDC (Change Data Capture) для публикации инкрементных изменений данных Postgres в Kafka, аналогично методу ввода данных Fivetran. Мы выбрали его вместе с Kafka за их масштабируемость, простоту настройки и тесную интеграцию с нашей существующей инфраструктурой.
- Hudi for Kafka → to → S3
Для ингестирования инкрементных данных из Kafka в S3 мы рассмотрели три отличных решения для создания озер данных и ингестирования: Apache Hudi, Apache Iceberg и DataBricks Delta Lake. В итоге мы выбрали Hudi за его отличную производительность при нашей нагрузке, связанной с обновлениями, а также за его открытый исходный код и встроенную интеграцию с CDC-сообщениями Debezium.
Iceberg и Delta Lake, с другой стороны, не были оптимизированы для нашей рабочей нагрузки с большим количеством обновлений, когда мы рассматривали их в 2022 году. В Iceberg также не было готового решения, понимающего сообщения Debezium; в Delta Lake такое решение есть, но оно не имеет открытого исходного кода. Нам пришлось бы реализовать собственный потребитель Debezium, если бы мы выбрали одно из этих решений.
Конструкторское решение 5: Получение необработанных данных перед обработкой
Наконец, мы решили загружать необработанные данные Postgres в S3 без обработки «на лету», чтобы создать единый источник истины и упростить отладку всего конвейера данных. Как только необработанные данные попадают в S3, мы выполняем трансформацию, денормализацию, обогащение и другие виды обработки данных. Промежуточные данные мы снова храним в S3, а в последующие системы для аналитики, составления отчетов и создания продуктов поступают только очень очищенные, структурированные и критически важные для бизнеса данные.
Масштабирование и эксплуатация нашего озера данных
Мы экспериментировали с множеством подробных настроек, чтобы решить проблемы масштабируемости, связанные с постоянно растущим объемом данных в Ноушен. Вот что мы попробовали и что из этого вышло:
1. Настройка коннектора CDC и Kafka
Мы установили по одному коннектору Debezium CDC на каждый хост Postgres и развернули их в кластере AWS EKS. Благодаря зрелости управления Debezium и EKS, а также масштабируемости Kafka, нам пришлось обновлять кластеры EKS и Kafka всего несколько раз за последние два года. По состоянию на май 2024 года он без проблем обрабатывает десятки МБ/с изменений строк Postgres.
Мы также настроили одну тему Kafka на таблицу Postgres и позволили всем коннекторам, потребляющим данные с 480 шардов, писать в одну и ту же тему для этой таблицы. Такая настройка значительно снизила сложность поддержания 480 тем для каждой таблицы и упростила последующую запись Hudi в S3, значительно снизив операционные накладные расходы.
2. Настройка худи
Мы использовали Apache Hudi Deltastreamer, Spark-based ingestion job, для потребления сообщений Kafka и репликации состояния таблицы Postgres в S3. После нескольких раундов настройки производительности мы создали быструю и масштабируемую систему ингестирования для обеспечения свежести данных. Эта настройка обеспечивает задержку всего в несколько минут для большинства таблиц и до двух часов для самой большой из них — таблицы блоков (см. график ниже).
- Мы используем стандартный тип таблицы COPY_ON_WRITE Hudi с операцией UPSERT, которая подходит для нашей рабочей нагрузки с большим количеством обновлений.
- Для более эффективного управления данными и минимизации усиления записи (т. е. количества файлов, обновляемых за один прогон пакетного ввода) мы настроили три конфигурации:
- Разбиение/шардирование данных с использованием той же схемы шардов Postgres, т. е. конфигурации
hoodie.datasource.write.partitionpath.field: db_schema_source_partition.Это разбивает набор данных S3 на 480 шардов, отshard0001доshard0480, что повышает вероятность того, что пакет входящих обновлений будет сопоставлен с одним и тем же набором файлов из одного и того же шарда. - Сортируйте данные по времени последнего обновления (event_lsn), т. е. по полю
source-ordering-field: event_lsn config.Это основано на нашем наблюдении, что более свежие блоки чаще обновляются, что позволяет нам отсеивать файлы, содержащие только устаревшие блоки. - Установите тип индекса для фильтра bloom, т.е. тип
hoodie.index.type: BLOOM,чтобы дополнительно оптимизировать рабочую нагрузку.

3. Настройка обработки данных Spark
Для большинства задач, связанных с обработкой данных, мы используем PySpark, относительно низкая скорость обучения которого делает его доступным для многих членов команды. Для более сложных задач, таких как обход деревьев и денормализация, мы используем превосходную производительность Spark в нескольких ключевых областях:
- Мы выигрываем от эффективности производительности Scala Spark.
- Мы эффективнее управляем данными, обрабатывая отдельно большие и маленькие шарды (помните, что мы сохранили ту же схему 480 шардов в S3, чтобы быть совместимыми с Postgres); маленькие шарды загружают все свои данные в память контейнера задач Spark для быстрой обработки, в то время как большие шарды, превышающие объем памяти, обрабатываются путем перетасовки дисков.
- Мы используем многопоточность и параллельную обработку для ускорения обработки 480 шардов, что позволяет нам оптимизировать время выполнения и эффективность.
4. Настройка бутстрапа
Вот как мы загружаем новые таблицы:
- Сначала мы настроим Debezium Connector для получения изменений Postgres в Kafka.
- Начиная с временной метки
t,мы запускаем задание export-to-S3, предоставляемое AWS RDS, чтобы сохранить последний снимок таблиц Postgres в S3. Затем мы создаем задание Spark для чтения этих данных из S3 и записи их в формат таблиц Hudi. - Наконец, мы гарантируем, что все изменения, сделанные в процессе создания снимков, будут зафиксированы, настроив Deltastreamer на чтение из Kafka сообщений от
t.Этот шаг очень важен для сохранения полноты и целостности данных.
Благодаря масштабируемости Spark и Hudi эти три этапа обычно завершаются в течение 24 часов, что позволяет нам выполнить перезагрузку с управляемым временем для размещения новых таблиц, обновления и решардинга Postgres.
Результат: меньше денег, больше времени, более мощная инфраструктура для ИИ
Мы начали разрабатывать инфраструктуру озера данных весной 2022 года и завершили ее к осени того же года. Благодаря свойственной инфраструктуре масштабируемости мы смогли постоянно оптимизировать и расширять кластеры Debezium EKS, кластеры Kafka, Deltastreamer и Spark job, чтобы соответствовать темпам удвоения данных в Ноушен, составляющим от 6 до 12 месяцев, без значительных перестроек. Это дало значительные результаты:
- Перемещение нескольких крупных, критически важных наборов данных Postgres (некоторые из них имеют размер в десятки ТБ) в озеро данных дало нам чистую экономию более миллиона долларов в 2022 году и пропорционально большую экономию в 2023 и 2024 годах.
- Для этих наборов данных время сквозного ввода данных из Postgres в S3 и Snowflake сократилось с более чем суток до нескольких минут для небольших таблиц и до пары часов для больших. При необходимости повторная синхронизация может быть выполнена в течение 24 часов без перегрузки живых баз данных.
- Что особенно важно, переход на новую систему позволил сэкономить на хранении, вычислениях и свежести данных для различных аналитических и продуктовых запросов, что обеспечит успешное развертывание функций Ноушен AI в 2023 и 2024 годах. Следите за подробным постом о нашей инфрастуктуре поиска и встраивания ИИ в RAG, построенной поверх озера данных!
Мы хотели бы поблагодарить компанию OneHouse и сообщество разработчиков открытого кода Hudi за их огромную и своевременную поддержку. Отличная поддержка открытого исходного кода сыграла решающую роль в том, что мы смогли развернуть озеро данных всего за несколько месяцев.
По мере роста и диверсификации наших потребностей мы продолжаем совершенствовать наше озеро данных, создавая автоматизированные и самообслуживаемые структуры, чтобы дать возможность большему числу инженеров управлять данными и разрабатывать на их основе сценарии использования продукта.
Хотите помочь нам создать следующее поколение системы управления данными Ноушен? Подайте заявку на наши открытые вакансии здесь.