До запуска бета-версии API Ноушен наша команда шутила, что каждый анонс продукта сопровождался общим рефреном:
NOTION: *помещает твит, в котором не упоминается API*.
ПОЛЬЗОВАТЕЛЬ: «Где API?»
Пользователи, желающие расширить возможности Ноушен, проявляли огромный интерес к API. Наша миссия заключается в том, чтобы сделать создание программных инструментов повсеместным. Чтобы эффективно выполнять эту задачу в современном взаимосвязанном мире, Ноушен должен работать с другими инструментами, на которые уже полагаются пользователи.
Многие пользователи справедливо задаются вопросом: «Разве создание REST API не является уже давно пройденным этапом? Что может быть такого сложного?» Это вполне обоснованные вопросы, особенно в мире, где API есть практически для всего — от данных фэнтези-спорта до рецензий на фильмы в New York Times. Что же отличает компанию Ноушен?
Оказалось, что разработка хорошего API для такой гибкой платформы, как Ноушен, представляет собой удивительно сложную задачу! Мы делимся некоторыми ключевыми решениями из нашего процесса, надеясь, что наш опыт поможет другим разработчикам и продемонстрирует, что делает API Ноушен уникальным.
Представление содержимого страницы
Ранее мы уже писали о модели данных Ноушен, но вкратце можно сказать следующее: контент делится на блоки. Блоком является все: от изображений и элементов списка до строк базы данных и самих страниц.
Суть проблемы разработки API заключается в том, как преобразовать произвольные деревья пользовательского контента с богатым форматом в последовательный API, легко интегрируемый с другими рабочими процессами. Давайте разделим эту проблему на две части: структурирование текста внутри блоков и иерархическая структура между блоками.
Встроенное форматирование насыщенного текста
Внутри каждого блока Ноушен поддерживает множество операций форматирования текста, начиная от стандартных полужирного и курсивного начертания и заканчивая выделением, уравнениями f(x) = x^2 + 1 и т.д. Не все эти стили являются стандартными, поэтому нам потребовалось переносимое представление и для текста.
Когда мы решали, как представлять содержимое страницы в API, было два основных претендента:
- Низкая точность, высокая переносимость: Markdown— популярный синтаксис для форматирования человекочитаемого текста. Это широко поддерживаемый формат с мощным инструментарием, а редактор Ноушен уже поддерживает ярлыки и экспорт Markdown.
- Высокая точность, низкая переносимость: Пользовательский JSON, в значительной степени основанный на нашем внутреннем представлении значений блоков Ноушен. Специально разработанная схема позволит учесть специфические для Ноушен типы блоков и их форматирование, но при этом потребует от пользователей каким-то образом преобразовывать эти данные в нужный им формат вывода.
Помимо компромисса между верностью и портативностью ядра, в пользу Markdown было высказано несколько соображений:
- Снижение нагрузки на внедрение и сопровождение: Мы хотели реализовать API как можно более эффективно. Использование формата Markdown позволило нам не разрабатывать новый формат данных, а использовать уже имеющиеся в Ноушен функции импорта и экспорта данных в формате Markdown.
- Меньше ломающих изменений: Плюсом низкой точности Markdown является то, что мы можем легко изменить способ представления блоков, используя ограниченное количество доступных конструкций. С другой стороны, при использовании пользовательского JSON каждый новый или обновленный тип блока потребует от нас модификации формата JSON и, возможно, выпуска новой версии API.
Однако самая большая проблема с Markdown заключается в том, что он просто недостаточно выразителен для поддержки тех сценариев использования, для которых наши пользователи хотели бы иметь API, например, пользовательских импортеров и экспортеров для ввода и вывода данных из Ноушен, или интеграций, использующих Ноушен в качестве CMS или резервного хранилища данных. Люди называют Ноушен «чистым холстом» и «местом для нестандартного мышления», потому что он настолько гибок и выразителен. Если бы наш API не мог воспроизвести то, на что пользователи потратили драгоценное время, создавая Ноушен, его мощность и полезность были бы снижены.

Разработчики часто удивляются, узнав, что канонический справочник по языку Markdown описывает относительно ограниченный набор конструкций форматирования.¹ Синтаксис для таблиц, зачеркивание в строке и огражденные блоки кода — функции, которые сегодня тесно связаны с Markdown, — появились только по мере того, как все больше людей стали адаптировать язык к своим потребностям, что вызвало кембрийский взрыв диалектов и инструментария (см. GitHub-Flavored Markdown, MultiMarkdown, PHP Markdown Extra, R Markdown, CommonMark и бесчисленные специальные реализации).
Документы, созданные в одном редакторе Markdown, часто по-разному обрабатываются и отображаются в другом приложении. Для простых документов эта несогласованность, как правило, устранима, но для богатой библиотеки блоков и опций встроенного форматирования Ноушен это большая проблема, многие из которых просто не поддерживаются ни в одной широко используемой реализации Markdown. Чтобы максимально точно сохранить пользовательский контент, мы решили разработать собственное JSON-представление для насыщенного текста.
Пагинация иерархий блоков
Еще одним достоинством пользовательского JSON является упрощение пагинации деревьев содержимого, что необходимо для извлечения больших страниц. Большинство блоков поддерживают неограниченное количество дочерних блоков, вложенных произвольно глубоко — представьте себе сложный контур списка или иерархию подстраниц рабочей области.
Такая неограниченная структура превращает, казалось бы, простой запрос, например, «получить содержимое страницы с рецептами», в более сложную проблему: как мы должны сортировать блоки содержимого в ответе?
- Breadth-first: Возвращать партии блоков верхнего уровня без дочерних блоков. Требовать от разработчиков отдельно запрашивать дочерние блоки для «завершения» отдельного блока. Эта модель имеет наибольший смысл с точки зрения производительности, однако получение полной страницы доставляет больше хлопот клиентам: им приходится делать больше запросов и выполнять вставку дерева для сборки ответов.
- Depth-first: Возврат полных блоков, при этом требуется больше вызовов для запроса блоков верхнего уровня, расположенных дальше по странице. Эта модель в большей степени соответствует интуиции большинства людей, считающих, что «возвращать содержимое нужно с самого начала и далее по странице». Однако маршаллинг одного глубоко вложенного блока может занять неограниченное количество времени, что сводит на нет смысл пагинации.
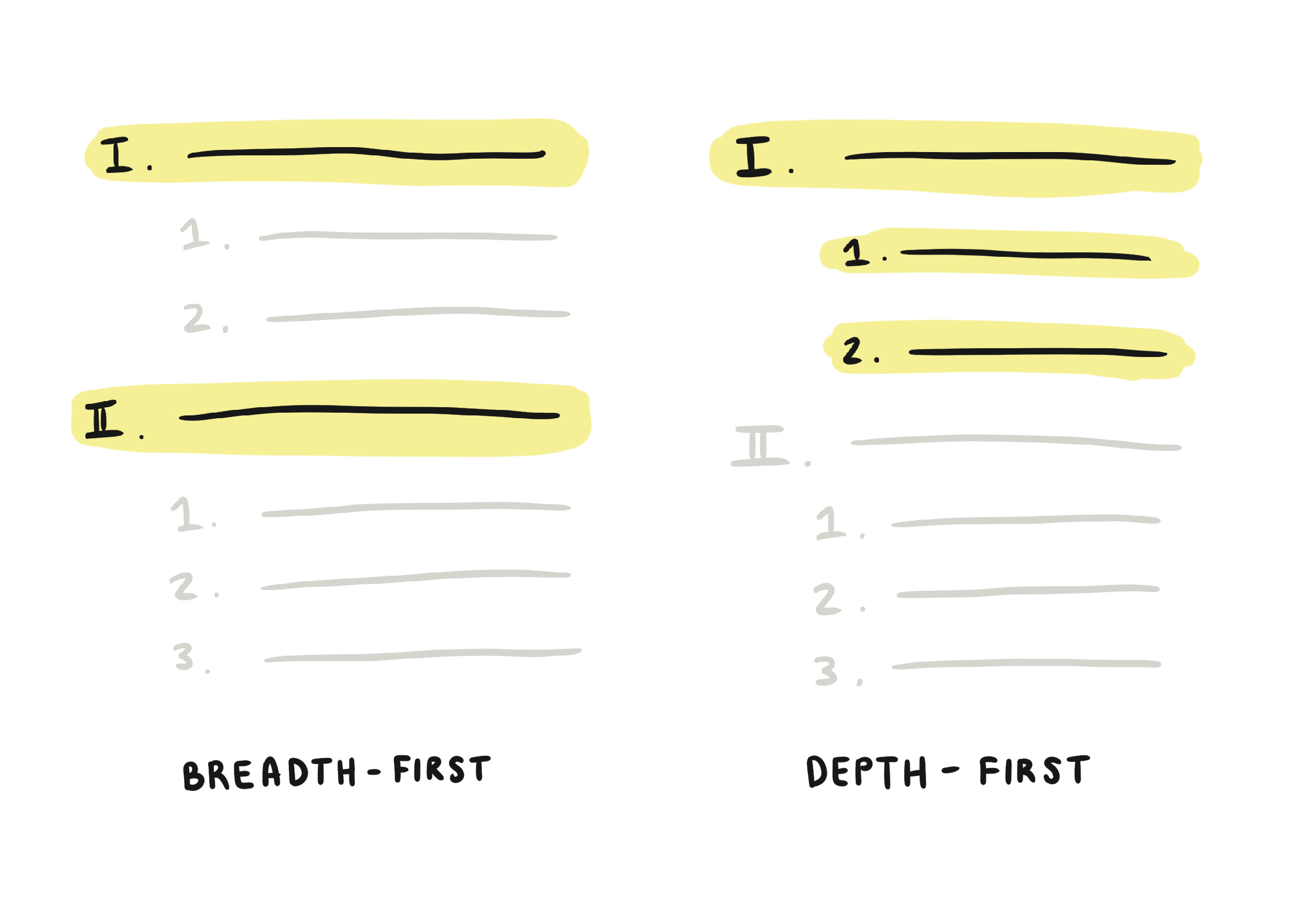
По соображениям производительности мы выбрали пагинацию в первую очередь, что напрямую повлияло на представление документов. Пагинация JSON довольно проста, поскольку блоки сохраняют свои UUID и другие структурные метаданные. Но поскольку документы Markdown не имеют особой структуры (кроме символов новой строки), их пагинация гораздо сложнее.
Например, в модели широты поиска нам придется обозначать неполные абзацы какими-либо маркерами. Эти маркеры нуждаются в идентификаторах, чтобы помочь клиентам вставить подпараграфы в правильное положение:
I. Введение ... <!-- 8215b034-6785-4082-a572-b9ce7fe6f8d0 --> II. Цели ... <!-- 2724af5c-8122-4127-a978-37067c37f745 -->Очень скоро нам пришлось бы изобретать еще один вариант Markdown и требовать от разработчиков выполнения множества операций со строками! Стало ясно, что простота Markdown не распространяется на нашу сложную модель документов, и мы решили использовать пользовательский JSON, чтобы обеспечить разработчикам большую точность и контроль.² В будущем наша команда (или сообщество разработчиков) всегда может создать инструменты конвертации для преобразования пользовательского JSON в стандартные форматы.
Выбор формата данных был сопряжен со смежным вопросом: как развивать API со временем. Здесь, как правило, существует два подхода:
- Версионность для каждого ресурса: Каждая конечная точка версионируется и обновляется индивидуально, либо по URI
(/v2/users), либо по заголовкуContent-Type(Accept: application/notion.v2+json). Версионность ресурсов позволяет вносить изолированные изменения, но при крупных обновлениях клиентам может потребоваться обновлять каждый URL, не говоря уже о головной боли, связанной с зависимостями между конечными точками (если для/v2/pagesтребуется/v3/databasesи т.п.).
- Глобальное версионирование: Любое изменение создает новую глобальную версию API. При принудительном использовании запросы должны содержать заголовок с указанием желаемой версии API, иначе предполагается, что используется версия, доступная на момент предоставления токена.
Мы выбрали глобальное версионирование, используя подход в стиле Stripe и AWS, когда вместо указания основных версий в URI(api-v2.notion.com) версии помечаются датой выпуска. Мы посчитали, что выпуск версий с указанием даты будет способствовать формированию этики небольших, безопасных переходов на новые версии с соответствующим недорогим обновлением, а не серьезных ломающих изменений, подразумеваемых при переходе от v2 к v3.
Получение свойств страницы
До сих пор мы говорили в основном о документах, созданных из текста. Но Ноушен предназначен не только для заметок и списков дел — мы также поддерживаем пользовательские базы данных. Страницы в базе данных могут иметь свойства, основанные на схеме базы данных. Поэтому нам потребовался способ запроса свойств страниц пользователями, и это оказалось на удивление непростой задачей!
Большинство свойств представляют собой простые значения, такие как персона, назначенная на проект, или список тегов. Когда пользователь запрашивает эти простые свойства страницы, мы можем просто вернуть JSON-представление базовых данных для каждого из них:

{ object: "property_item", type: "url", url: "https://notion.so", }Пример JSON-представления для свойства URL, ссылающегося на https://notion.so.
Мы также поддерживаем более сложные свойства страниц, такие как отношения и сворачивание. Эти свойства делают Ноушен особенно мощным инструментом для реляционного моделирования данных.
- Отношения позволяют пользователям связывать страницы в различных базах данных.Например, предположим, что вы являетесь владельцем малого бизнеса, занимающегося продажей одежды. У вас может быть база данных 🔖 Products, содержащая цену каждого изделия и другие сведения о производстве, и база данных 👥 Customers, содержащая постоянных покупателей. Создание связи между этими базами данных позволяет отслеживать, кто что купил, причем в обоих направлениях.

- Свертки используются для объединения свойств связанных страниц.Свертка состоит из трех компонентов: связанной базы данных, свойства из этой базы и операции, выполняемой над этим свойством. Например, для определения лучших клиентов можно настроить свойство rollup в 👥 Customers, чтобы показать, сколько потратил каждый клиент:
- Сопутствующая база данных: 🔖 Продукты
- Недвижимость: Цена (число)
- Эксплуатация:
Сумма
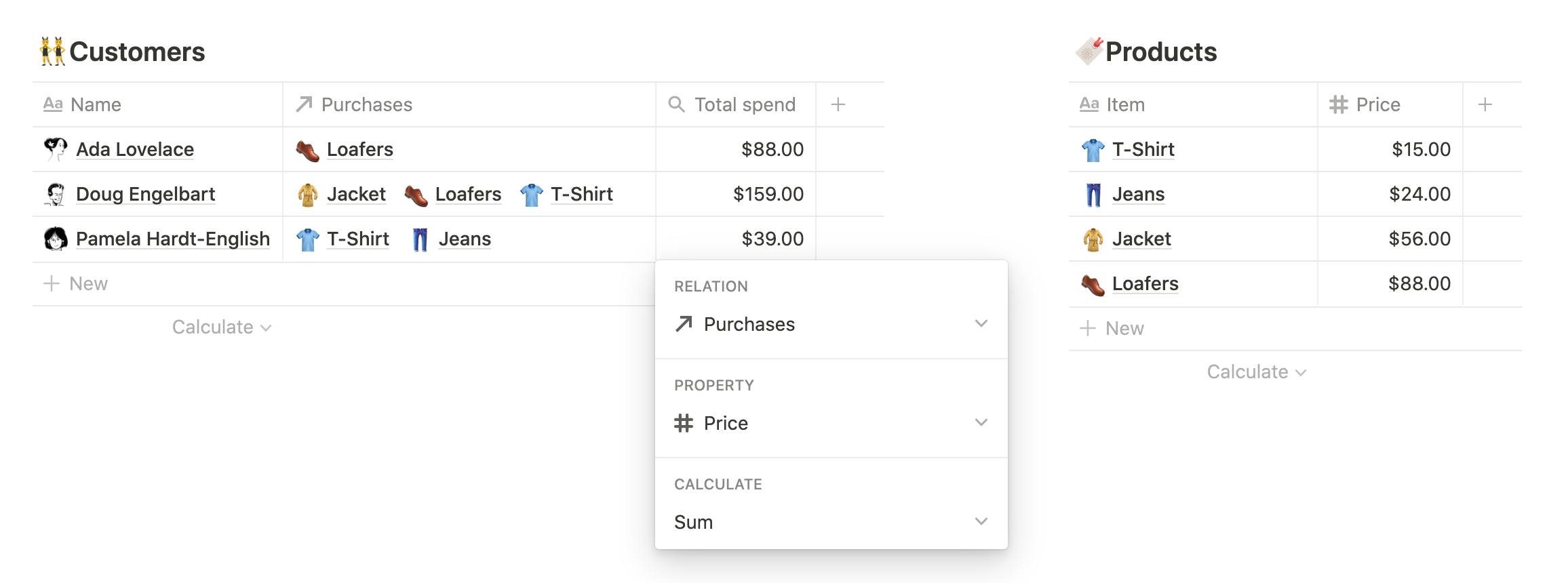
Для каждого покупателя сворачивание просматривает все приобретенные товары, извлекает цену каждого товара и суммирует их.
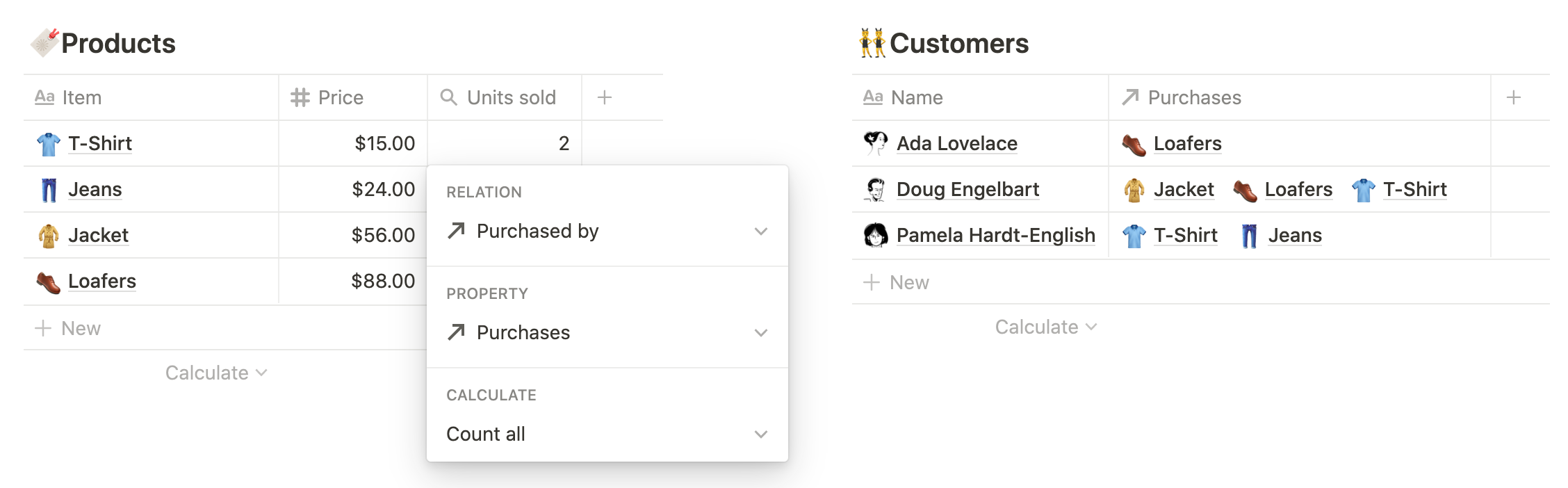
Свертывание не ограничивается числовыми свойствами: можно обобщать и связанные страницы. Здесь мы настраиваем сворачивание для базы данных 🔖 Products, чтобы отслеживать, сколько раз был продан каждый продукт.
- Сопутствующая база данных: 👥 Клиенты
- Недвижимость: Покупки (отношение)
- Операция:
Подсчитать все
Внутри системы мы храним отношения в нормализованном виде. Это означает, что для данной страницы товара связанные с ней клиенты хранятся в виде массива UUID страниц, которые служат внешними ключами для базы данных 👥 Customers.
Очевидно, что мы не можем отобразить эти UUID непосредственно пользователю, поэтому при загрузке отношения нам необходимо искать каждую связанную страницу, чтобы получить ее человекочитаемые свойства. Это означает, что загрузка одного свойства отношения может вызвать множество поисков: по одному для каждой связанной страницы в другой базе данных!
Свертки добавляют еще один уровень сложности. Поскольку сворачивание объединяет свойства всех связанных страниц, вычисление сворачивания начинается с загрузки свойства отношения, как описано выше. Затем, в зависимости от операции, мы должны извлечь соответствующее свойство из каждой связанной страницы и агрегировать свойства страниц. Простые операции, такие как Count all, достаточно просты, но такие операции, как Sum или Average, требуют отслеживания промежуточного состояния.

Каково же практическое значение всего этого? Чем больше отношений и сворачиваний включено в страницу, тем больше поисков и маршалинга необходимо выполнить API, и тем больше будет время отклика. Для корпоративного использования неограниченная задержка станет огромной проблемой.
Пагинация отношений
Стандартным решением для вычисления данных произвольного размера является пагинация: вместо того чтобы загружать и возвращать все результаты сразу, мы выдаем по одному пакету фиксированного размера, предоставляя клиенту хэндл для запроса следующей порции результатов.
Пагинация предполагает, что ваши результаты могут быть упорядочены. Существует два основных способа, позволяющих клиентам ориентироваться в этом порядке:
- Основанные на смещении: Просты для разработчиков, но могут быть рассинхронизированы, если базовые данные обновляются в реальном времени.
"размер": 50, " смещение": 150Запросчики указывают размер партии и числовой индекс в списке результатов.
{ " results": [...], " count": 24, " done": true}В ответе может быть указано, есть ли дополнительные результаты, которые необходимо получить.
- Курсоры: Курсоры могут представлять собой ссылки на состояния прокрутки на стороне сервера или непосредственно кодировать параметры запроса с помощью Base 64 или аналогичной кодировки.
{ "size": 50, "смещение": 150}Запросчики указывают размер партии и, по желанию, курсор из предыдущего ответа.
{ " results": [...], " cursor": "aHR0cHM6Ly93d3cueW91dHViZS5jb20vd2F0Y2g/dj1kUXc0dzlXZ1hjUQ=="
}Ответ включает курсор на следующую партию.
Поскольку пользователи могут обновлять отношения в режиме реального времени, мы решили реализовать пагинацию на основе курсора для загрузки свойств отношения. Это позволяет нам возвращать ограниченное количество страниц из свойства отношения, а клиенты могут выполнять дополнительные запросы до тех пор, пока не будут возвращены все страницы.

Пагинация числовых сверток
Мы можем использовать эту логику пагинации для роллапов, поскольку загрузка роллапа требует загрузки базового отношения. Но есть одна загвоздка: как и формулы электронных таблиц, сворачивания вычисляются в реальном времени на основе связанных страниц, а поскольку мы загружаем связанные страницы постепенно, у нас может не быть всех данных, необходимых для вычисления окончательного значения сворачивания!
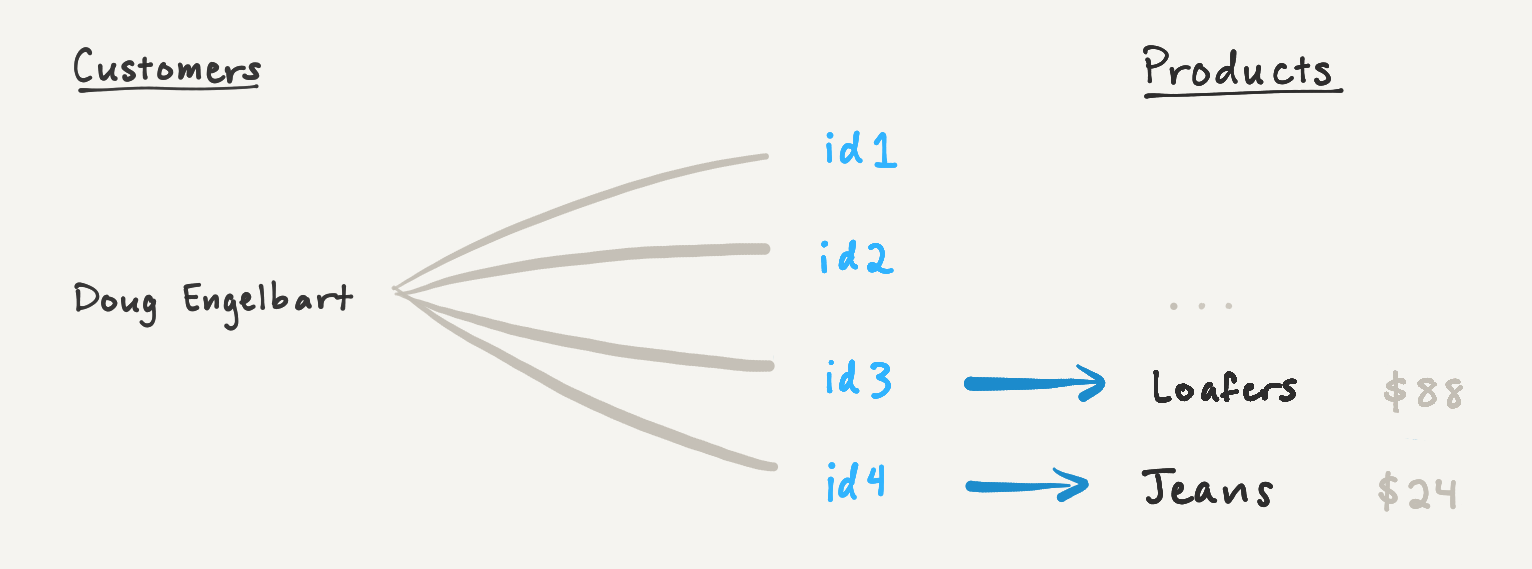
Для иллюстрации вернемся к ролику «Total Spend», который суммирует стоимость всех покупок одежды Дуга Энгельбарта. Если мы будем загружать отношение «Покупки» партиями по два раза, то первый ответ будет содержать только общую стоимость загруженных на данный момент страниц, что не отражает общую сумму расходов Дага.
{ " relations": [ { "id": "id1" }, { "id": "id2" } ] " sum": 71}В агрегатном состоянии для суммы партии хранится сумма на данный момент. Значение 71 вместе со смещением в списке отношений [2, 71] хэшируется в курсоре.
{ " results": [...], " cursor": "tVaBfEdSY2"}В следующем запросе курсор декодируется в агрегатное состояние { «sum»: 71 } и используется для вычисления суммы всех партий на данный момент.
Однако мы можем вычислить частичный результат для первых двух страниц и хэшировать его в курсоре в качестве аккумулятора. Когда клиент сделает еще один запрос к курсору, мы сможем обновить накопитель на основе вновь загруженных страниц. К моменту загрузки всех страниц накопитель будет отражать окончательное значение сворачивания.
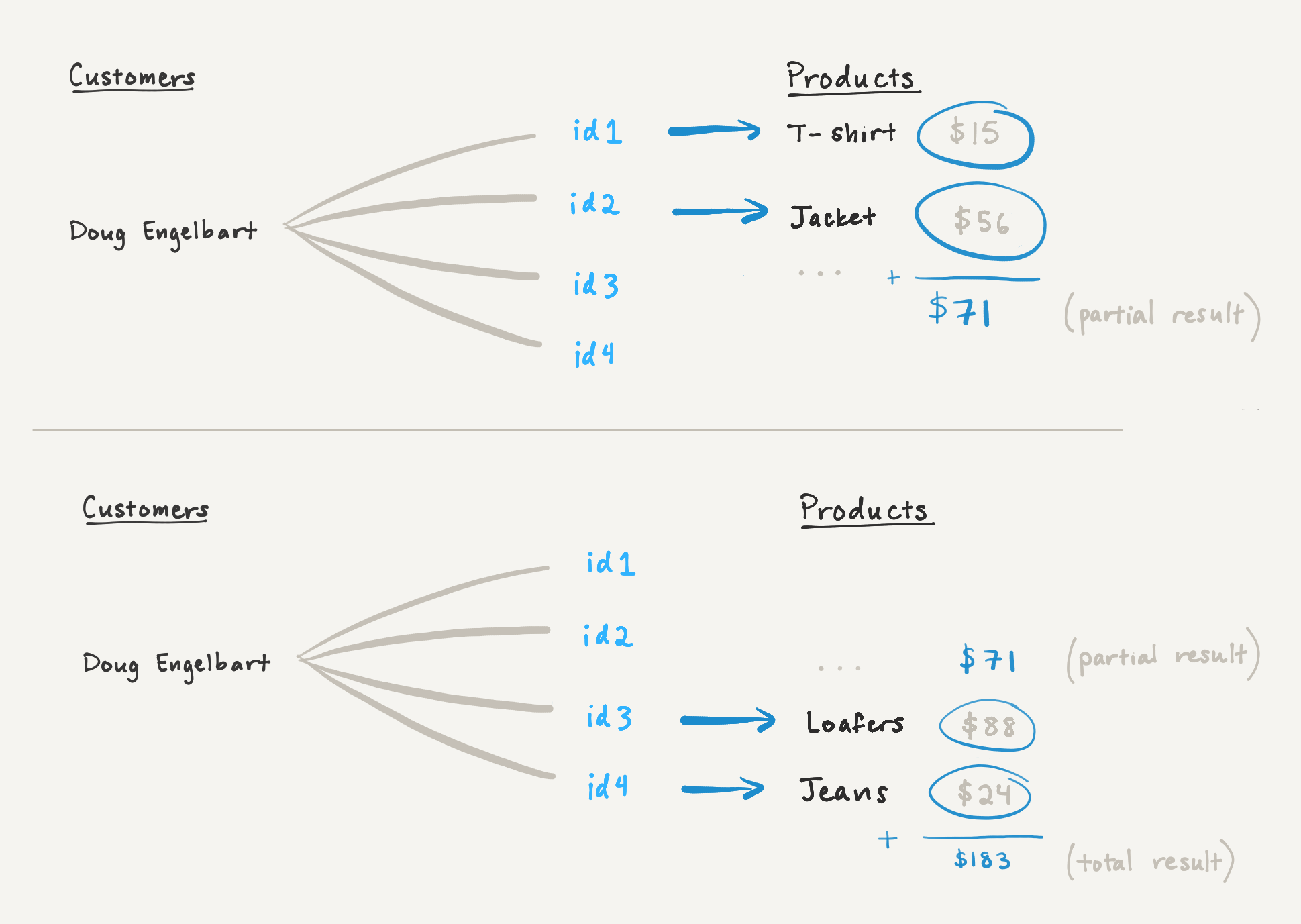
Для постраничной обработки сворачивания суммы мы вычисляем частичную сумму для каждого пакета связанных страниц. Каждый ответ содержит курсор, кодирующий следующую страницу и частичную сумму всех загруженных на данный момент страниц. Последующие извлечения могут включать эту частичную сумму до тех пор, пока не будут загружены все страницы и сумма не будет отражать всю связь.
Кодирование результата в курсоре работает для многих видов сверток, включая Sum, Count и Max. Для Average нам также необходимо отслеживать количество загруженных страниц, чтобы правильно взвесить частичное среднее. В более общем случае наш подход работает для любого сворачивания, обладающего следующими свойствами:
- Досадно параллельны: Мы можем разделить проблему на независимые подпроблемы и объединить частичные результаты, чтобы в итоге получить общий результат. Это требование исключает рулоны типа
Median, которые не могут быть разделены на подзадачи, пока все страницы не будут глобально упорядочены, что потребует загрузки всех страниц для начала. - Сублинейное представление пространства: Для того чтобы закодировать их в курсоре без ущерба для эргономики, нам необходимо, чтобы размер аккумулятора(ов) рос медленно. Например,
SumиAverageявляются константными пространствами в JavaScript, где все числа занимают 64 бита независимо от размера. Это требование исключает использование рулонов типаShow unique values, который поддается распараллеливанию (достаточно вычислить уникальные значения в каждом подмножестве), но требует линейно увеличивающегося объема (для кодирования всех уникальных значений, встречающихся на данный момент). Такой курсор в Base64-кодировке быстро станет громоздким.
Для тех немногих типов сворачиваний, которые мы не можем использовать MapReduce, мы просто возвращаем значения базовых отношений, чтобы клиент мог вычислить их напрямую.
Строительство для наших пользователей
При таком высоком спросе на API было бы легко отступить от принципов качества в пользу быстрого получения результата. Но мы хотели, чтобы API соответствовал обещаниям самого Ноушен: мощный, гибкий инструмент, который можно приспособить для решения своих задач. Иногда для достижения этой цели приходится идти сложным путем: вводить пользовательское JSON-представление страниц, внедрять версионность до запуска бета-версии или разрабатывать новую схему пагинации для обработки сложных зависимостей данных.
Однако тяжелая работа приносит еще больше плодов, когда пользователи создают невероятные вещи с помощью созданных нами инструментов. Если вы хотите попробовать бета-версию API, зайдите на наш сайт для разработчиков и начните работу. А если вы мечтаете о каком-то конкретном функционале, перейдите на страницу карьеры, чтобы начать работу и в этом направлении.