В начале этого года мы отключили Ноушен на пять минут для планового обслуживания. В то время как в нашем объявлении говорилось о «повышении стабильности и производительности», за кулисами скрывалась кульминация месяцев целенаправленной и срочной работы команды: разделение монолита PostgreSQL в Ноушен на горизонтально разделенный парк баз данных.
Хотя переход на новую систему прошел с ликованием, мы сохраняли спокойствие на случай возникновения каких-либо заминок после миграции. К нашей радости, пользователи быстро заметили улучшения:
Но одно окно технического обслуживания не дает полной картины. Наша команда потратила месяцы на разработку архитектуры этого перехода, чтобы сделать Ноушен быстрее и надежнее на долгие годы.
Позвольте мне рассказать вам историю о том, как мы делали шардинг и чему научились на этом пути.
Решение о том, когда делать шардинг
Sharding стал важной вехой в нашем постоянном стремлении повысить производительность приложений. За последние несколько лет нам было приятно и радостно наблюдать, как все больше и больше людей внедряют Ноушен во все сферы своей жизни. И неудивительно, что все новые вики компании, трекеры проектов и покедексы означали миллиарды новых блоков, файлов и пространств для хранения. К середине 2020 года стало ясно, что использование продуктов превысит возможности нашего надежного монолита Postgres, который исправно служил нам на протяжении пяти лет и четырех порядков роста. Инженеры, приехавшие по вызову, часто просыпались от скачков процессора базы данных, а простые миграции только по каталогам стали небезопасными и неопределенными.
Когда речь заходит о шардинге, быстрорастущим стартапам приходится идти на тонкий компромисс. В девяностые годы в блогах появилось множество сообщений о вреде преждевременного перехода на шардинг: увеличение нагрузки на обслуживание, новые ограничения в коде на уровне приложений и зависимость от архитектурных путей.¹ Конечно, при наших масштабах переход на шардинг был неизбежен. Вопрос был только в том, когда.
Для нас точка перегиба наступила, когда процесс Postgres VACUUM начал постоянно останавливаться, не позволяя базе данных освободить дисковое пространство от мертвых кортежей. Хотя емкость диска можно увеличить, более тревожной была перспектива обхода идентификатора транзакции (TXID)— защитного механизма, при котором Postgres прекращает обработку всех записей, чтобы не повредить существующие данные. Осознав, что обход TXID представляет собой экзистенциальную угрозу для продукта, наша инфраструктурная команда удвоила усилия и приступила к работе.
Проектирование схемы шардинга
Если вы никогда раньше не использовали «чередование» баз данных, то вот в чем суть: вместо вертикального масштабирования базы данных с помощью все более мощных экземпляров, используйте горизонтальное масштабирование путем разделения данных на несколько баз. Теперь вы можете легко запустить дополнительные узлы для обеспечения роста. К сожалению, теперь ваши данные находятся в разных местах, поэтому необходимо разработать систему, обеспечивающую максимальную производительность и согласованность в распределенной среде.
Разделение на уровне приложений
Мы решили реализовать собственную схему разбиения и маршрутизировать запросы из логики приложения, что называется шардингом на уровне приложения. В ходе наших первоначальных исследований мы также рассматривали пакетные решения для шардинга/кластеризации, такие как Citus для Postgres или Vitess для MySQL. Хотя эти решения привлекают своей простотой и предоставляют возможность работы с кросс-шардингом из коробки, реальная логика кластеризации непрозрачна, а нам нужен был контроль над распределением наших данных.²
Разделение на уровне приложений потребовало от нас принятия следующих проектных решений:
- Какие данные следует разделять? Уникальность нашего набора данных заключается в том, что таблица
блоковотражает деревья пользовательского контента, которые могут сильно различаться по размеру, глубине и коэффициенту ветвления. Например, один крупный корпоративный клиент генерирует нагрузку, превышающую нагрузку многих средних персональных рабочих пространств вместе взятых. Мы хотели разделить только необходимые таблицы, сохранив при этом локальность для связанных данных. - Как следует разбивать данные? Хорошие ключи разбиения обеспечивают равномерное распределение кортежей по шардам. Выбор ключа разбиения также зависит от структуры приложения, поскольку распределенные соединения являются дорогостоящими, а гарантии транзакционности обычно ограничиваются одним хостом.
- Сколько шардов мы должны создать? Как эти шарды должны быть организованы? Это касается как количества логических шардов на одну таблицу, так и конкретного отображения логических шардов на физические хосты.
Решение 1: Разделить все данные, транзитивно связанные с блоком
Поскольку модель данных Ноушен основана на концепции блока, каждый из которых занимает строку в нашей базе данных, таблица блоков была наиболее приоритетной для шардинга. Однако блок может ссылаться на другие таблицы, такие как space (рабочие пространства) или discussion (потоки обсуждений на уровне страницы и внутри страницы). В свою очередь, обсуждение может ссылаться на строки таблицы комментариев и т.д.
Мы решили разделить все таблицы, доступные из таблицыблоков по каким-либо отношениям внешнего ключа. Не все эти таблицы нуждались в шардировании, но если запись хранилась в основной базе данных, а связанный с ней блок — на другом физическом шарде, то при записи в разные хранилища данных могли возникнуть несоответствия.
Решение 2: Разбиение блочных данных по идентификатору рабочей области
После того как мы определились с таблицами для разбиения, необходимо было разделить их на части. Выбор хорошей схемы разбиения в значительной степени зависит от распределения и связности данных; поскольку Ноушен — продукт, основанный на командной работе, следующим нашим решением было разделение данных по идентификаторам рабочих пространств.³
Каждому рабочему пространству при создании присваивается UUID, поэтому мы можем разбить пространство UUID на однородные блоки. Поскольку каждая строка в таблице шардирования является либо блоком, либо связана с ним, а каждый блок принадлежит ровно одному рабочему пространству, мы использовали идентификатор рабочего пространства в качестве ключа разделения. Поскольку пользователи обычно запрашивают данные в рамках одной рабочей области за раз, мы избегаем большинства межосколочных соединений.
Решение 3: Планирование мощностей
Определившись со схемой разбиения, мы поставили перед собой задачу разработать такую систему шардирования, которая бы справлялась с имеющимися данными и масштабировалась в соответствии с прогнозом двухлетнего использования без особых усилий. Вот некоторые из наших ограничений:
- Тип экземпляра: Пропускная способность дискового ввода-вывода, выраженная в IOPS, ограничена как типом экземпляра AWS, так и объемом диска. Для удовлетворения существующего спроса нам требовалось не менее 60 тыс. суммарных IOPS с возможностью дальнейшего масштабирования в случае необходимости.
- Количество физических и логических шардов: Чтобы обеспечить работу Postgres и сохранить гарантии репликации RDS, мы установили верхнюю границу в 500 Гбайт на таблицу и 10 Тбайт на физическую базу данных. Нам нужно было выбрать количество логических шардов и количество физических баз данных, чтобы шарды можно было равномерно распределить между базами данных.
- Количество экземпляров: Большее количество экземпляров означает более высокую стоимость обслуживания, но более надежную систему.
- Стоимость: Мы хотели, чтобы наш счет масштабировался линейно по отношению к нашей базе данных, а также чтобы мы могли гибко масштабировать вычислительное и дисковое пространство по отдельности.
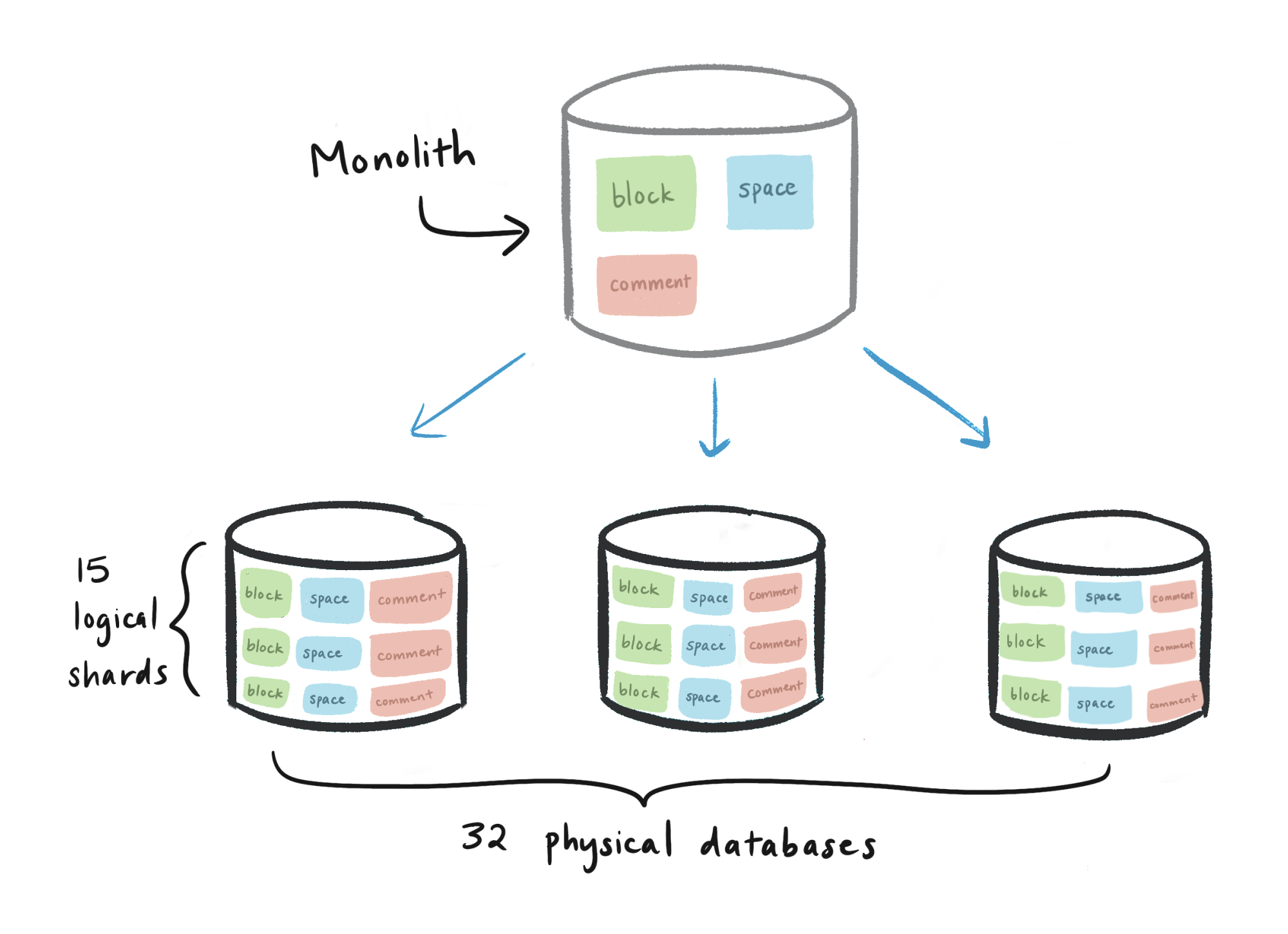
Проанализировав цифры, мы остановились на архитектуре, состоящей из 480 логических шардов, равномерно распределенных по 32 физическим базам данных. Иерархия выглядела следующим образом:
- Физическая база данных (всего 32)
- Логический шард, представленный в виде схемы Postgres (15 на базу данных, всего 480)
- таблица
блоков(1 на логический шард, всего 480) - таблица
сбораданных (1 на логический шард, всего 480) - таблица
пространства(1 на логический шард, всего 480) - и т.д. для всех таблиц с шардированием
- таблица
- Логический шард, представленный в виде схемы Postgres (15 на базу данных, всего 480)
Выбор 480 обусловлен многими факторами:
2
3
4
5
6
8
10, 12, 15, 16, 20, 24, 30, 32, 40, 48, 60, 80, 96, 120, 160, 240
Дело в том, что 480 делится на множество чисел, что обеспечивает гибкость при добавлении или удалении физических хостов с сохранением равномерного распределения шардов. Например, в будущем мы можем масштабировать систему с 32 до 40 и 48 хостов, делая каждый раз инкрементные переходы.
Для сравнения, предположим, что у нас 512 логических шардов. Все коэффициенты 512 равны степени 2, то есть, чтобы сохранить равномерное распределение шардов, нам придется перейти от 32 к 64 хостам. Любой коэффициент, равный 2, потребует удвоения числа физических хостов для увеличения масштаба. Выбирайте значения с большим количеством коэффициентов!
Мы решили построить schema001.block, schema002.block и т.д. в виде отдельных таблиц, а не поддерживать одну таблицу блоков с разбиением на базы данных с 15 дочерними таблицами. Таблицы с естественным разделением вводят еще одну часть логики маршрутизации:
- Код приложения: идентификатор рабочей области → физическая база данных.
- Таблица разделов: идентификатор рабочей области → логическая схема.
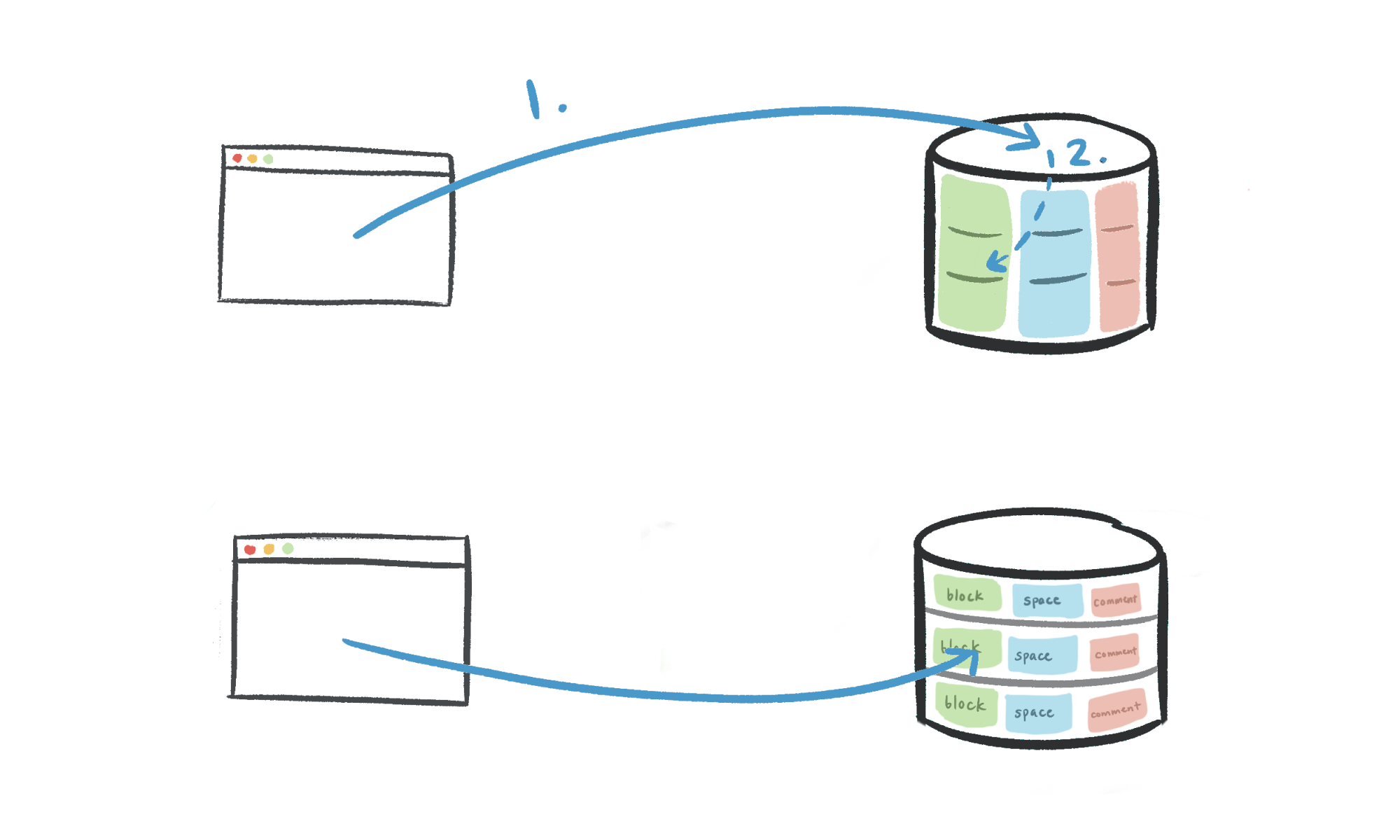
Нам нужен был единый источник истины для маршрутизации от идентификатора рабочей области к логическому шарду, поэтому мы решили построить таблицы отдельно и выполнить всю маршрутизацию в приложении.
Переход на шарды
После того как мы создали схему шардинга, пришло время ее реализовать. Для любой миграции наша общая схема выглядит следующим образом:
- Двойная запись: Входящие записи применяются как к старой, так и к новой базе данных.
- Обратное заполнение: После начала двойной записи перенесите старые данные в новую базу данных.
- Верификация: Убедитесь в целостности данных в новой базе.
- Переключение: Фактический переход на новую базу данных. Это можно сделать постепенно, например, выполнить двойное чтение, а затем перенести все чтения.
Двойная запись в журнале аудита
Фаза двойной записи обеспечивает заполнение новыми данными как старой, так и новой базы данных, даже если новая база данных еще не используется. Существует несколько вариантов двойной записи:
- Запись непосредственно в обе базы данных: Казалось бы, все просто, но любая проблема с записью может быстро привести к несоответствиям между базами данных, что делает этот подход слишком ненадежным для производственных хранилищ данных критического пути.
- Логическая репликация: Встроенная функциональность Postgres, использующая модель публикации/подписки для трансляции команд в несколько баз данных. Ограниченная возможность модификации данных между исходной и целевой базами данных.
- Журнал аудита и сценарий подхвата: Создайте таблицу журнала аудита для отслеживания всех записей в переносимые таблицы. Процесс подхвата итеративно просматривает журнал аудита и применяет каждое обновление к новым базам данных, внося в них необходимые изменения.
Мы выбрали стратегию аудиторского журнала вместо логической репликации, поскольку последняя с трудом справлялась с объемом записи в таблицу блоков на этапе начального моментального снимка.
Заполнение старых данных
После того как входящие записи были успешно перенесены в новые базы данных, мы запустили процесс обратной заливки для переноса всех существующих данных. При использовании всех 96 процессоров (!) на выделенном нами экземпляре m5.24xlarge окончательный сценарий заполнения производственной среды занял около трех дней.
Любая достойная обратная заливка должна сравнивать версии записей перед записью старых данных, пропуская записи с более поздними обновлениями. Если запустить сценарий догоняющего и обратного заполнения в любом порядке, то новые базы данных в конечном итоге сблизятся и будут копировать монолит.
Проверка целостности данных
Миграция хороша только при условии целостности базовых данных, поэтому после обновления осколков в монолите мы начали процесс проверки корректности.
- Сценарий верификации: Наш скрипт проверял смежный диапазон пространства UUID, начиная с заданного значения, сравнивая каждую запись в монолите с соответствующей записью в шарде. Поскольку полное сканирование таблицы было бы непомерно дорогим, мы произвольно выбирали UUID и проверяли их смежные диапазоны.
- «Темное» чтение: Перед миграцией запросов на чтение мы добавили флаг для получения данных как из старой, так и из новой базы данных (так называемое » темное чтение«). Мы сравнивали эти записи и отбрасывали шардированную копию, регистрируя в процессе расхождения. Внедрение «темного чтения» увеличило задержку API, но дало уверенность в том, что переход на новую базу данных пройдет без проблем.
В качестве меры предосторожности логика переноса и верификации была реализована разными людьми. В противном случае возрастала вероятность того, что кто-то допустит одну и ту же ошибку на обоих этапах, что ослабляло предпосылки верификации.
Непростые уроки
Хотя большая часть проекта по созданию шардинга запечатлела лучшие качества инженерной команды Ноушен, было много решений, которые мы бы пересмотрели, оглядываясь назад. Вот несколько примеров:
- Shard раньше. Будучи небольшой командой, мы прекрасно понимали, какие компромиссы несет в себе преждевременная оптимизация. Однако мы ждали, пока существующая база данных будет сильно нагружена, а это означало, что мы должны были быть очень экономными с миграциями, чтобы не увеличивать нагрузку. Это ограничение не позволило нам использовать логическую репликацию для двойной записи. ID рабочей области — наш ключ раздела — в старой базе данных еще не был заполнен, и обратное заполнение этого столбца увеличило бы нагрузку на наш монолит. Вместо этого мы заполняли каждую строку на лету при записи на шарды, что потребовало создания собственного сценария подхвата.
- Стремитесь к миграции без простоя. Пропускная способность двойной записи была основным узким местом в нашем финальном переключении: как только мы отключили сервер, нам нужно было дать скрипту catch-up завершить распространение записей на шарды. Если бы мы потратили еще неделю на оптимизацию скрипта, чтобы он тратил <30 секунд на подхват шардов во время переключения, то, возможно, удалось бы провести горячую замену на уровне балансировщика нагрузки без простоев.
- Внедрение комбинированного первичного ключа вместо отдельного ключа раздела. Сегодня строки в таблицах, разделенных на группы, используют комбинированный ключ:
id— первичный ключ старой базы данных иspace_id— ключ раздела текущей. Поскольку нам все равно придется выполнять полное сканирование таблицы, мы могли бы объединить оба ключа в один новый столбец, избавившись от необходимости передаватьspace_idпо всему приложению.
Несмотря на все эти сложности, шардинг имел огромный успех. Для пользователей Ноушен несколько минут простоя сделали продукт ощутимо быстрее. Внутри компании мы продемонстрировали слаженную командную работу и решительное выполнение поставленной задачи.
Если сжатые сроки не мешают вам тщательно продумать долгосрочные технические последствия, мы будем рады пообщаться с вами — присоединяйтесь к нам!